
Fast R-CNN Understanding
Giới thiệu
Trong bài trước chúng ta đã tìm hiểu về mô hình R-CNN. Nhận thấy mô hình R-CNN có một số nhược điểm sau:
- Nhiều stage: CNN để trích xuất features, Linear SVM và regressor for bounding boxes
- Trong quá trình training cần lưu lại các extracted feature vector của tất cả các classes và background. Sau đó mới train SVM được. Việc này dẫn đến tốn rất nhiều bộ nhớ
- Thời gian training và inference rất lâu. Không có sự chia sẻ tính toán, từng region proposal lần lượt được đưa vào ConvNet.
Và sau 1 năm từ ngày R-CNN được đề xuất Girshick đã đưa ra mô hình cải tiến hơn với tên gọi Fast R-CNN để giải quyết các hạn chế trên.
Không giống như R-CNN từng region proposal được được qua ConvNet thì ở Fast R-CNN ảnh sẽ được đưa qua ConvNet. Điều này giúp chia sẻ tính toán và cũng giảm thời gian training xuống rất nhiều do nhiều region proposals chồng chập với nhau.
Sau khi đưa ảnh qua ConvNet chúng ta nhận được feature map (output sau Conv layer cuối cùng). Dựa vào Selective Search chúng ta xác định được các region proposals và vị trí của nó trên ảnh gốc. Từ đây có thể dễ dàng xác định được phần feature map tương ứng với từng region proposal. Từng feature map này được đưa qua RoI pooling layer và một số FC layers để phân loại và tinh chỉnh bounding box.
Dưới đây là kiến trúc của Fast R-CNN
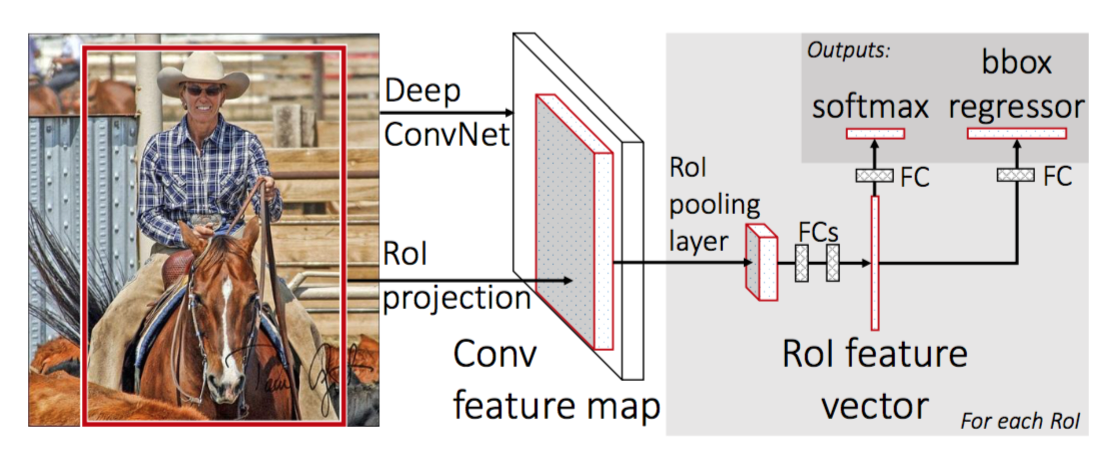
Hiểu đơn giản có 2 nhánh cho 2 outputs và tính loss trên các outputs đó như bình thường.
RoI pooling layer
Như đã nói ở trên sau khi đưa ảnh qua ConvNet chúng ta sẽ thu được feature map. Từ đây có thể xác định được phần nào của feature map tương ứng với từng region proposal, quá trình này gọi là RoI Projection. Tuy nhiên kích thước của các phần này khác nhau chúng cần resize lại về cùng một kích thước. Điều này cần thiết vì sau đó chúng ta có sử dụng FC layers để đảm bảo khớp dimensions (nếu phía sau toàn là Conv layers thì không cần).
Làm sao chúng ta xác định được phần nào của feature map thuộc về region proposal nào?
Đầu tiên cùng làm quen với khái niệm sub-sampling ratio - tỉ lệ kích thước của feature map và ảnh ban đầu.

Sau khi biết được sub-sampling ratio và vị trí của region proposal (từ Selective Search) trong ảnh ban đầu chúng ta sẽ xác định được phần RoI tương ứng trên feature map với RoI trong ảnh ban đầu.
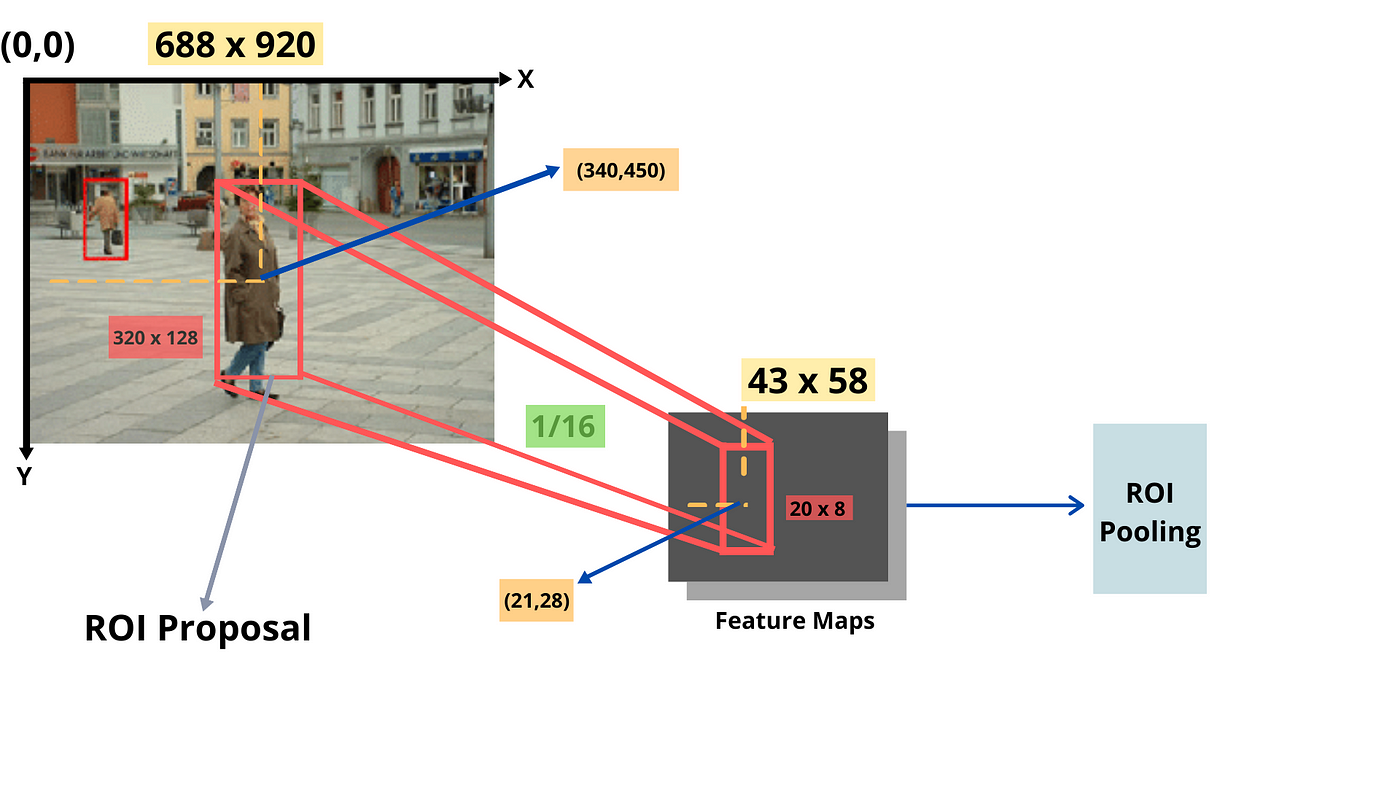
Như ví dụ trên ảnh ban đầu có kích thươc 668x920 và feature map có kích thước 43x58, sub-sampling ratio = 1/16. Trong ảnh ban đầu region proposal có kích thước 320x128, do đó kích thước của nó trong feature map là 20x8. Tọa độ tâm của region proposal trong ảnh ban đầu là (340, 450), trong feature map tương ứng là (21, 28), cứ theo tỉ lệ 1/16 áp dụng vào thôi.
Ở đây có 2 cách xác định vị trí của box:
- Biết tọa độ tâm, height và width
- Biết tọa độ của góc trên bên trái và góc dưới bên phải
Ở đây chúng ta đang nói theo cách 1. Cách số 2 cũng làm tương tự như trên. Sau khi xác định phần feature map tương ứng của region proposal chúng ta đưa nó qua RoI pooling layer để nhận được đầu ra có kích thước cố định. Chúng ta tạm thời không cần để ý đến số channels, ở đây làm cho một channel, các channels còn lại cũng tương tự.
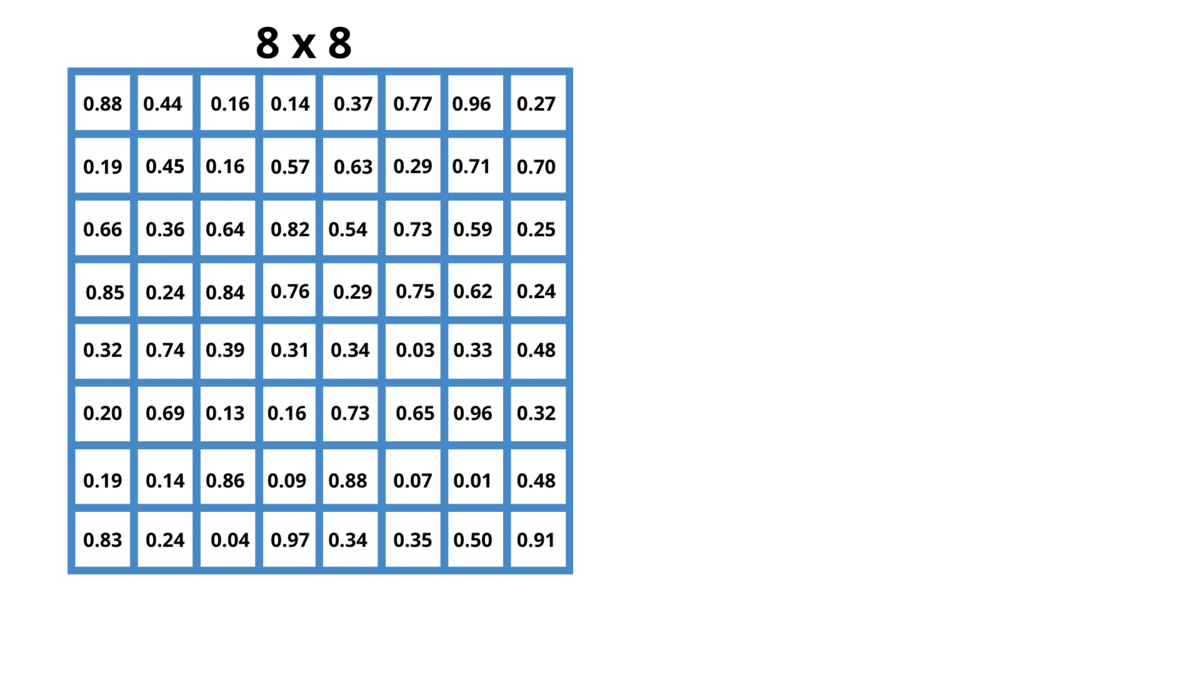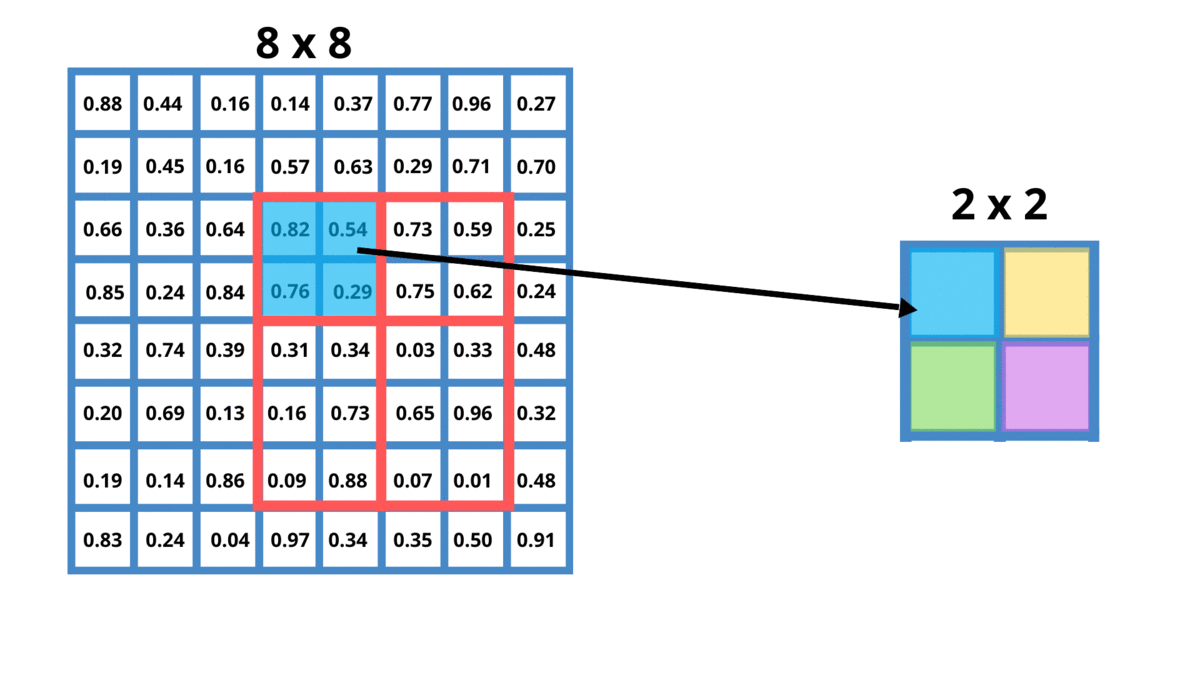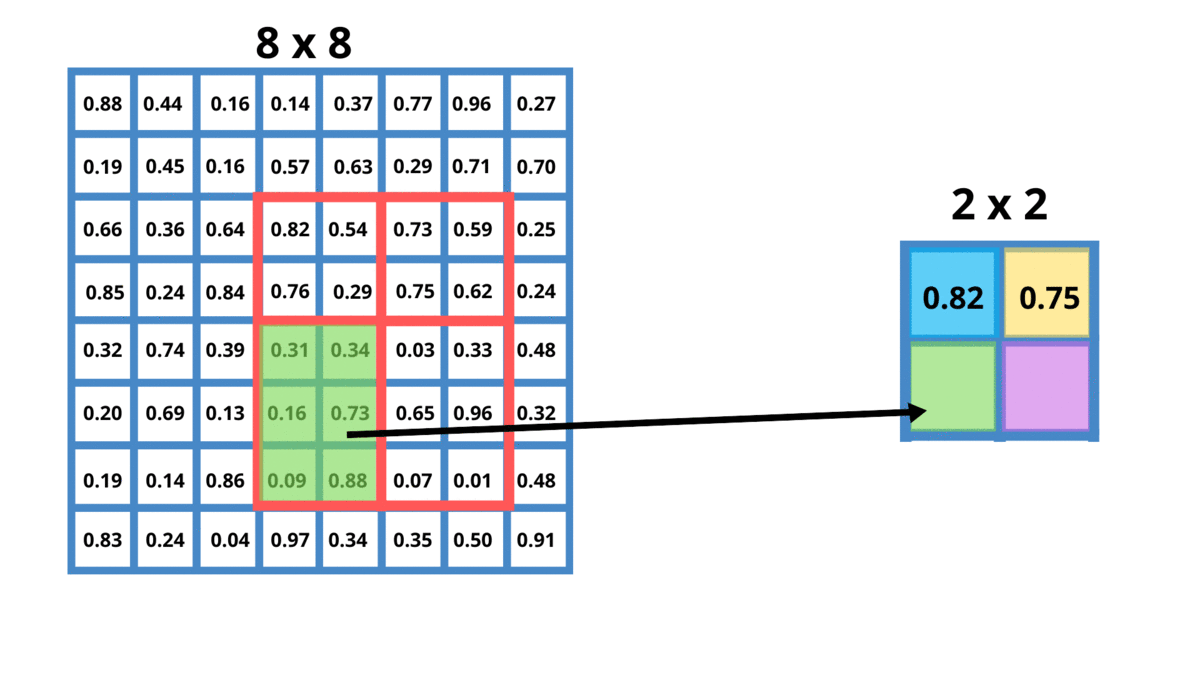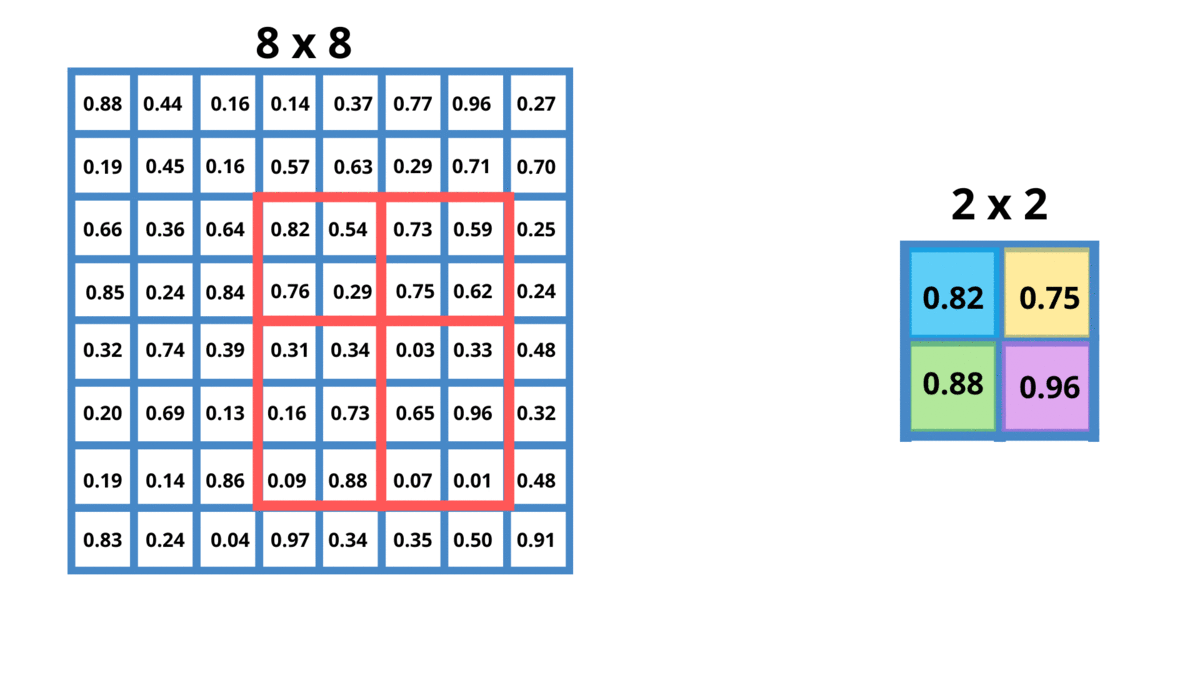
Như hình bên trên phần vùng màu đỏ - feature map của roi proposal có kích thước 4x5 chúng ta đang đưa nó về output có kích thước 2x2.
Ví dụ ban đầu phần feature map có kích thước hxw, chúng ta muốn đưa về kích thước HxW. Điều này được thực hiện như sau:
- Chiều width
wchúng ta chia thànhWphần. Mỗi phần có kích thước làw//W, riêng phần cuối có kích thước làw//W + w%W(trường hợpwkhông chia hết choW) - Chiều height
hchia thànhHphần. Mỗi phần có kích thước làh//H, riêng phần cuối có kích thước làh//H + h%H. - Trong mỗi grid cell sẽ áp dụng Max Pooling operation để lấy một giá trị duy nhất
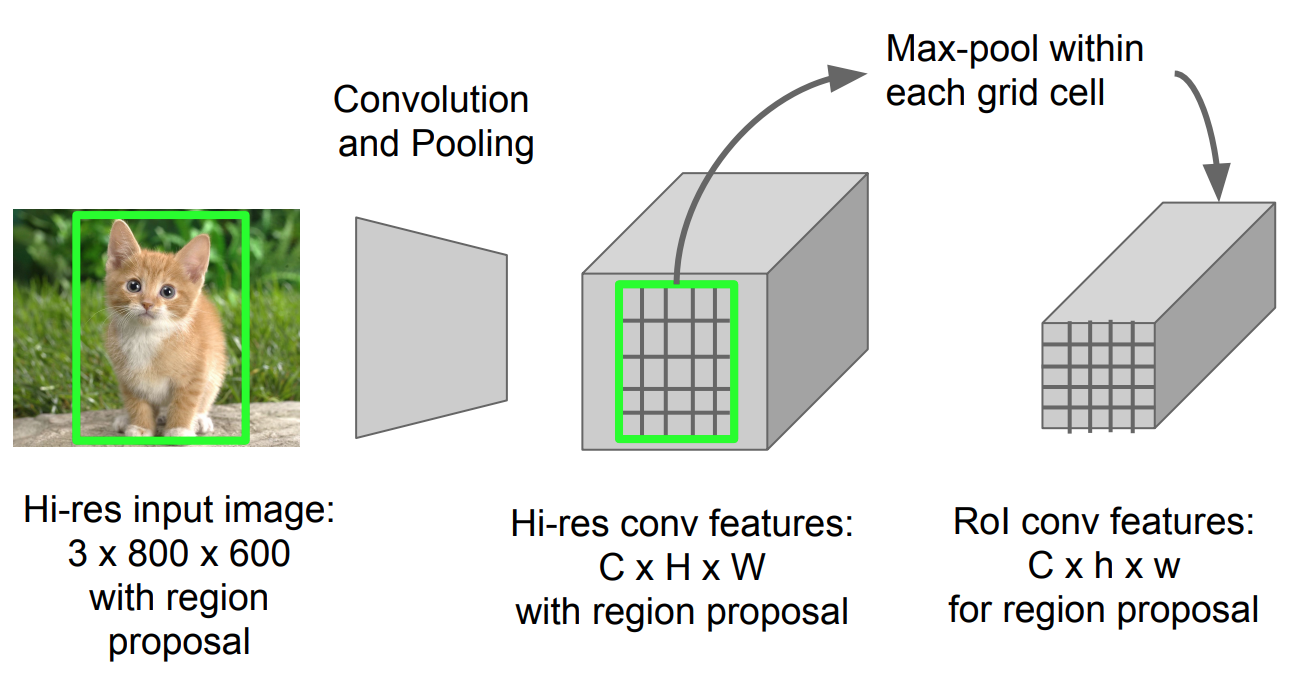
Trong Fast R-CNN các RoI được đưa về kích thước 7x7 (chưa tính số channels) - đầu ra của RoI pooling layer. Nhắc lại một lần nữa feature map thường là output của Conv layer cuối cùng. Lớp Max Pooling cuối trong mạng pre-trained model loại bỏ đi, ở đây đã được thay thể bằng RoI pooling layer. Các bạn có thể tham khảo chi tiết hơn về RoI pooling layer tại đây.
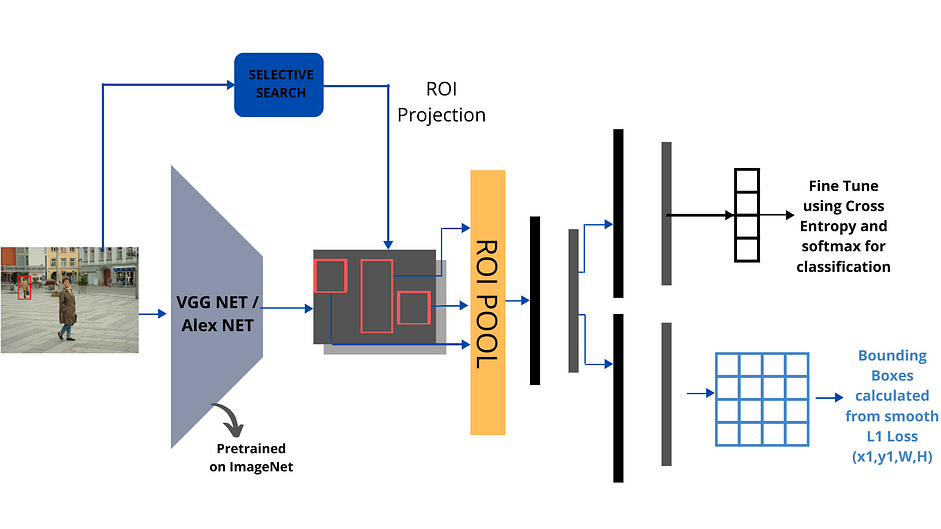
Fast R-CNN không còn sử dụng Linear SVM để phân loại các classes. Thay vào đó nó sử dụng softmax layer để phân loại.
Fast R-CNN
Các bước hoạt động chính của Fast R-CNN 1. Pre-trained model trên tập ImageNet (lấy luôn pre-trained model)
2. Sử dụng selective search để xác định các region proposals
3. Thay đổi pre-trained model:
- Thay thế Max pooling layer cuối cùng bằng RoI pooling layer. RoI pooing layer đưa ra feature vectors với kích thước cố định.
- Thay thế FC layer cuối cùng và Softmax layer bằng FC layer và softmax layer cho $K+1$ classes (+1 vì tính cả background)
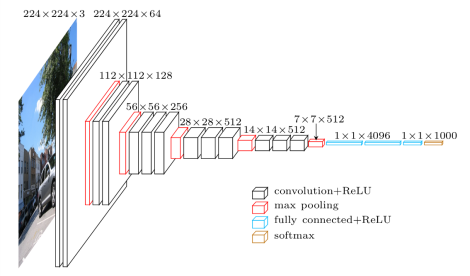
VGG16 architecture
4. Thêm một nhánh để tinh chỉnh bounding box (làm tương tự R-CNN)
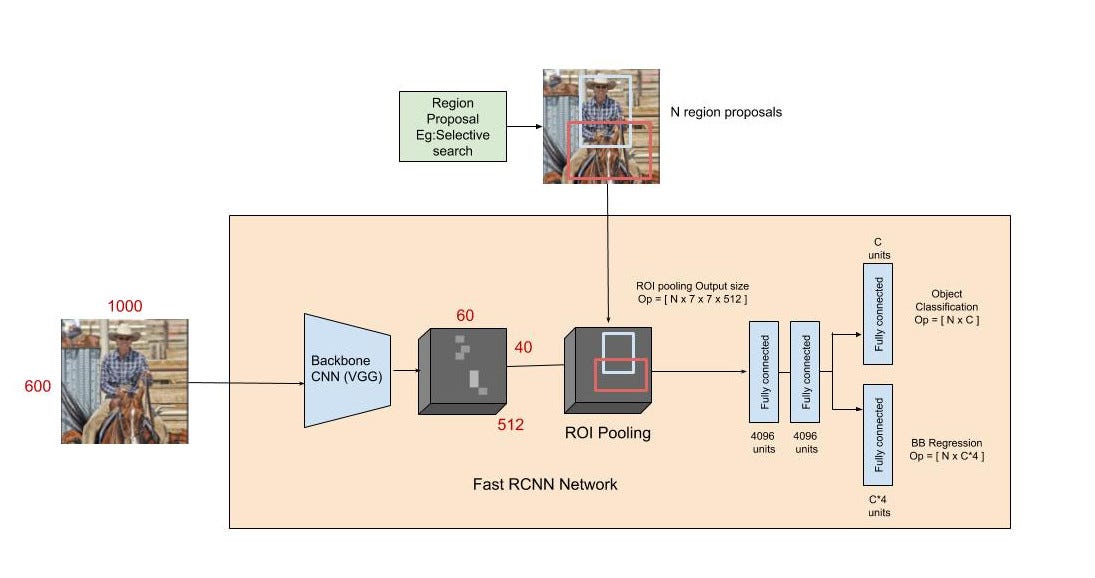
Như hình trên chúng ta nhận thấy không có sự gián đoạn trong việc trích xuất feature vector và việc dự đoán các classes cũng như tinh chỉnh box. Tuy nhiên chúng ta vẫn còn sử dụng Selective Search để tạo ra các region proposals.
Loss function
Fast R-CNN sử dụng multi-task loss. Dưới đây là một số kí hiệu:
- $u$ - true label class, $u \in 0, 1, \dots, K$. $u=0$ tương ứng với background
- $p$ - xác suất tương ứng với các class cho từng RoI, $p = (p_0, \dots, p_K)$, các giá trị này được lấy từ softmax layer.
- $v$ - true bounding box target, $v = (v_x, v_y, v_w, v_h)$. Các giá trị này chính là offsets của ground-truth bounding box so với RoI.
- $t^u$ - predicted bounding box correction, $t^u = (t^u_x, t^u_y, t^u_w, t^u_h)$. Cái này cũng tương tự như mô hình R-CNN. Các giá trị này chính là offsets của predicted bounbing box so với RoI. Nếu các giá trị này trùng với các giá trị ở trên thì predicted bounding box sẽ trùng với ground truth bounding box.
Mỗi training RoI được gán nhãn với true label class $u$ và true bounding box target $v$. Đối với background nó không có ground-truth bounding box do đó loss của background bằng 0. Chúng ta đưa vào kí hiệu sau:
\[\mathbb{1} [u >= 1] = \begin{cases} 1 & \text{if } u \geq 1\\ 0 & \text{otherwise} \end{cases}\]Khi đó multi-task loss sẽ là:
\[\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box}\] \[\begin{align*} \mathcal{L}(p, u, t^u, v) &= \mathcal{L}_\text{cls} (p, u) + \mathbb{1} [u \geq 1] \mathcal{L}_\text{box}(t^u, v) \\ \mathcal{L}_\text{cls}(p, u) &= -\log p_u \\ \mathcal{L}_\text{box}(t^u, v) &= \sum_{i \in \{x, y, w, h\}} L_1^\text{smooth} (t^u_i - v_i) \end{align*}\]Bounding box loss đo sự khác nhau giữa $t^u_i$ và $v_i$. Thay vì dùng Ridge regression loss như R-CNN ở đây dùng L1 smooth loss (không nhạy với các outliers).
\[L_1^\text{smooth}(x) = \begin{cases} 0.5 x^2 & \text{if } \vert x \vert < 1\\ \vert x \vert - 0.5 & \text{otherwise} \end{cases}\]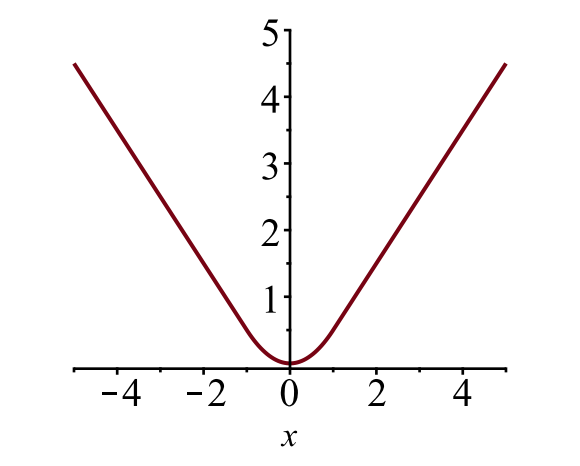
Đồ thị của $L_1^\text{smooth}(x)$
Đánh giá
- Fast R-CNN đã giải quyết các hạn chế của R-CNN. Nhờ việc chia sẻ tính toán mà tốc độ training và inference cải thiện rất nhiều (có nhiều region chồng chập với nhau).
- Fast R-CNN vẫn còn sử dụng dụng Selective Search để tạo region proposals. Chính cái này là bottleneck làm giới hạn performance của Fast R-CNN, điều này có thể nhận thấy ở hình thứ 2 bên dưới với test time của Fast R-CNN khi cần Selective Search để tạo region proposals. Lúc này thời gian để xử lý một ảnh lên đến hơn 2s. Đây chính là nhược điểm làm Fast R-CNN không chạy được real time.
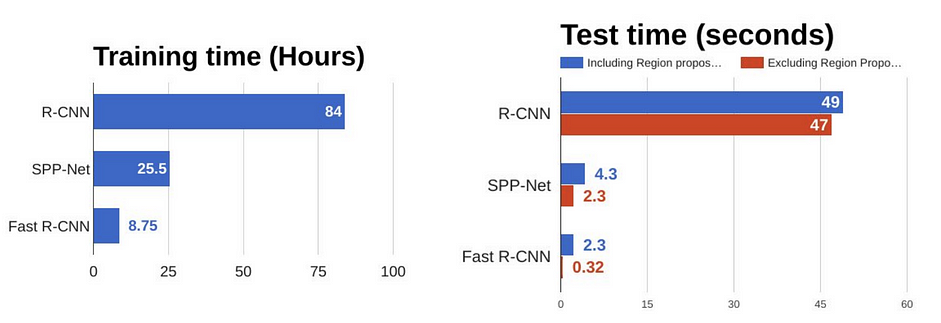
Như vậy chúng ta đã cùng tìm hiểu về mô hình Fast R-CNN. Hy vọng mọi người tìm thấy điều gì hữu ích từ bài viết này.
Tài liệu tham khảo
- https://arxiv.org/abs/1504.08083
- https://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html
- https://towardsdatascience.com/understanding-fast-r-cnn-and-faster-r-cnn-for-object-detection-adbb55653d97
- https://towardsdatascience.com/fast-r-cnn-for-object-detection-a-technical-summary-a0ff94faa022
- https://www.youtube.com/watch?v=UF4YqCE_1UA&list=PLANbacZNzD9HEbQ-CkACLyAqC3f0U9Plp&index=5
- https://github.com/huytranvan2010/Fast-R-CNN-Understanding
- https://towardsdatascience.com/understanding-region-of-interest-part-1-roi-pooling-e4f5dd65bb44