
Feature Pyramid Network (FPN) Understanding
Mở đầu
Phát hiện vật thể với nhiều kích thước khác nhau được coi là thách thức lớn, đặc biệt với vật thể nhỏ. Chúng ta có thể sử dụng image pyramid để phát hiện vật thể, tuy nhiên quá trình xử lý sẽ tốn rất nhiều thời gian. Chúng ta có thể sử dụng chúng trong các cuộc thi, nơi độ chính xác được đặt cao hơn so với tốc độ. Ngoài ra chúng ta có thể tạo pyramid of feature để phát hiện vật thể. Các feature map gần với ảnh chứa low-level feature và thường không hiệu quả trong object detection.
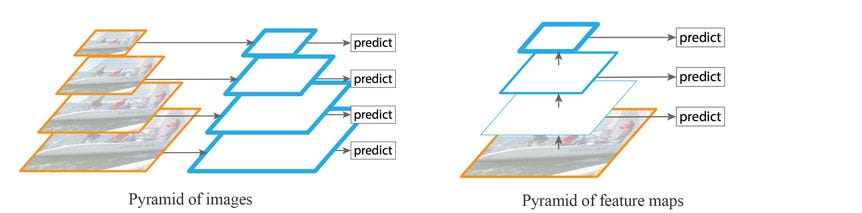
Hình trên biểu diễn 2 cách làm thông thường:
- Pyramid of image: tạo nhiều ảnh với scale khác nhau sau đó thực hiện object detection với từng ảnh đó
- Pyramid of feature maps: chỉ sử dụng một ảnh nhưng sử dụng nhiều feature maps liên tiếp để thực hiện object detection (feature map gần ảnh ban đầu cho kết quả kém hơn do chứa low-level features)
Feature Pyramid Network (FPN) là feature extractor được thiết kế dựa trên pyramid concept với độ chính xác và hiệu suất tốt hơn. FPN thay thế feature extractor của detector như Faster R-CNN và tạo ra nhiều feature map layers (multi-scale feature maps) với thông tin chất lượng hơn feature pyramid thông thường cho bài toán object detection.
Data Flow

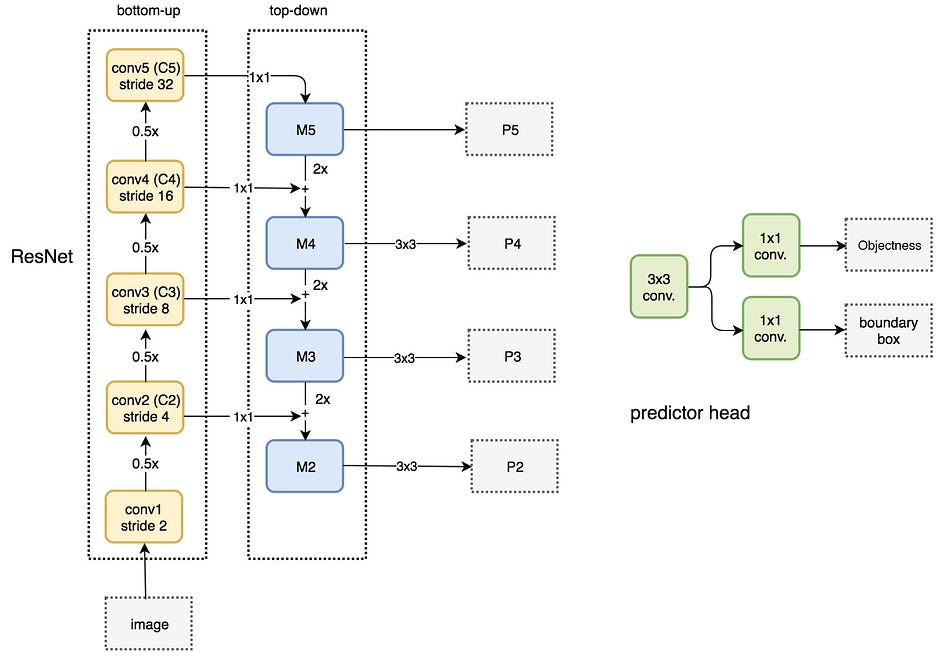
Như hình trên FPN chứa 2 thành phần chính gọi là bottom-up và top-down.
Phần bottom-up là mạng CNN thông thường cho feature extraction. Theo chiều mũi tên đi lên thì spatial resolution giảm (kích thước width x height của output các layer giảm). Đồng thời trong các feature map bên trên chúng ta phát hiện được high-level features, nói cách khác semantic value tăng lên.
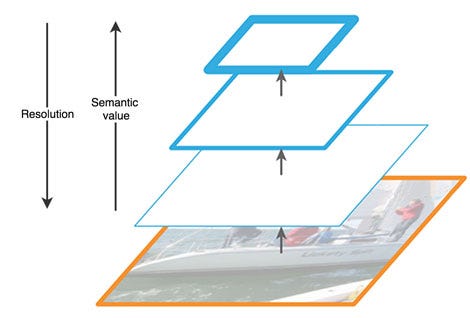
Bottom-up pathway of FPN
Nhớ lại SSD (Single shot multibox detector) thực hiện detection từ multiple feature maps. Tuy nhiên các bottom layers không được chọn cho object detection. Chúng có high resolution nhưng semantic value (giá trị về mặt ngữ cảnh) không đủ để có thể sử dụng. Do đó SSD chỉ sử dụng các upper layers cho detection, chính điều này làm SSD khó phát hiện các vật thể nhỏ.
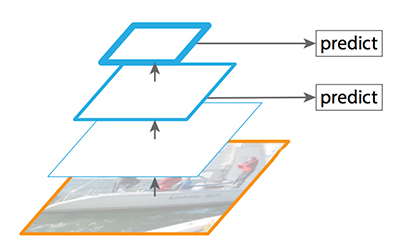
Feature maps dùng để detection trong SSD
Để tránh nhược điểm của SSĐ, FPN có sử dụng top-down pathway để xây dựng lại higher resolution layer từ semantic rich layer (xây dựng lại layers có độ phân giải cao hơn từ các layers chứa high-level feature).
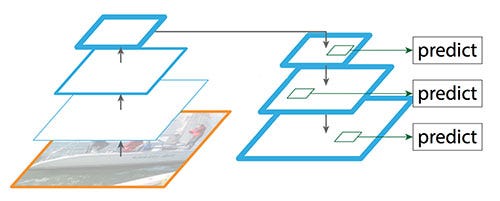
Reconstruct spatial resolution in the top-down pathway
Nhận thấy reconstructed layers (các layers tái tạo) chứa nhiều ngữ nghĩa (semantic strong) nhưng vị trí của objects không được chính xác sau các quá trình downsampling (giảm kích thước) và upsampling (tăng kích thước). Chính vì vậy chúng ta sẽ thêm lateral connection (kết nối bên) giữa reconstructed layers và feature maps (bên bottom-up pathway) tương ứng để giúp detection dự đoán chính xác hơn vị trí của vật thể. Điều này cũng giống skip connection trong mô hình ResNet giúp quá trình training dễ dàng hơn.
Thêm các lateral connection (skip connection)
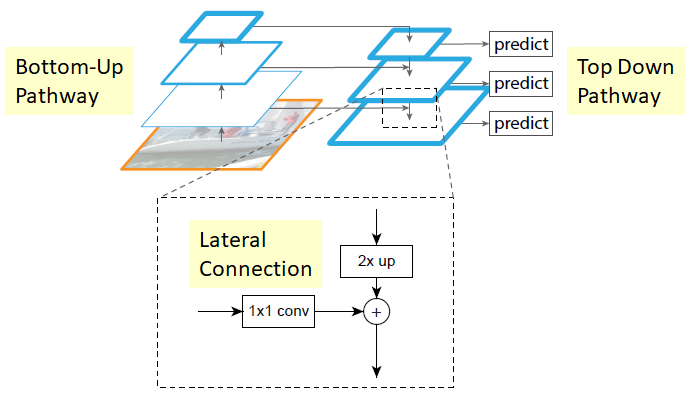
Skip connection
Bottom-up pathway
Bottom-uppathway sử dụng model ResNet. Nó chứa rất nhiều convolution modules (Convi for i=1..5), mỗi module có một vài Conv layers. Theo chiều mũi tên đi lên spatial resolution giảm một nửa (stride tăng lên gấp đôi). Đầu ra của mỗi convolution module được đánh số là Ci (sẽ được sử dụng trong top-down pathway).
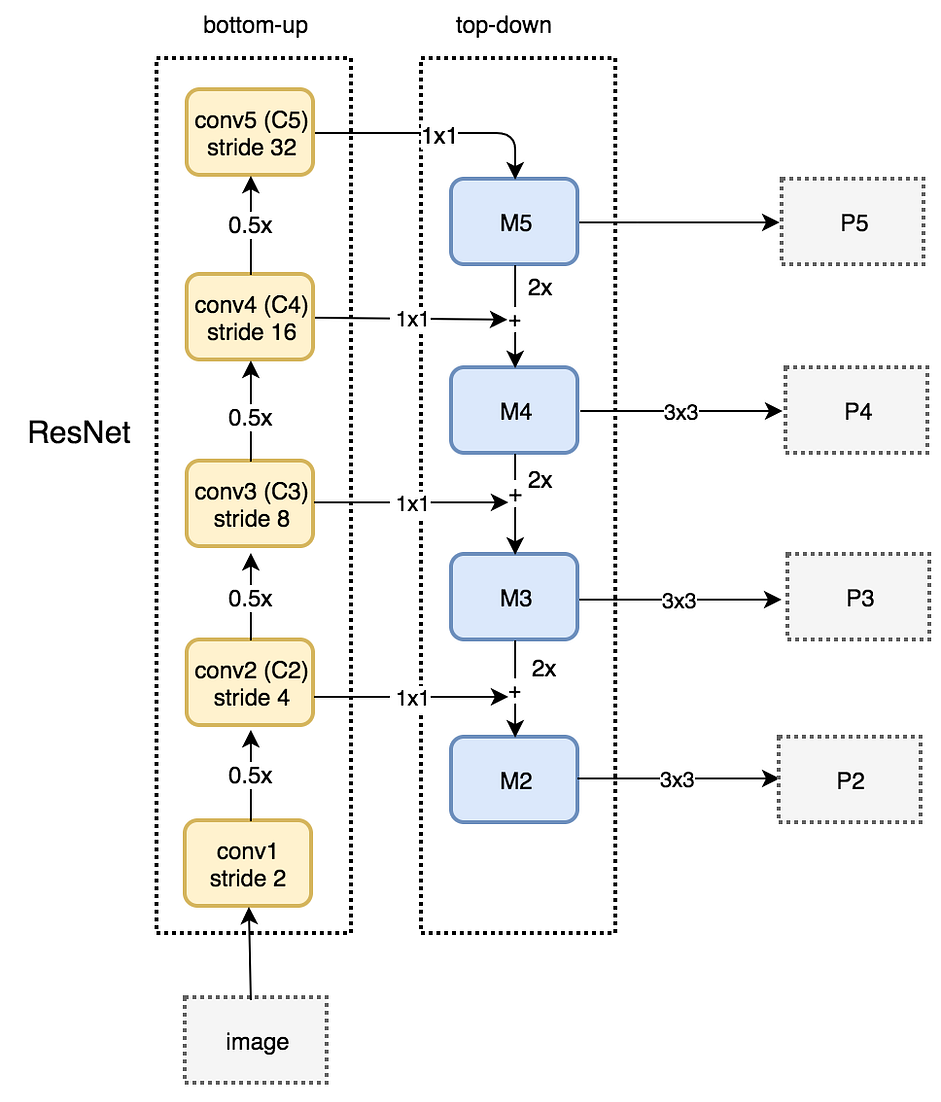
Top-down pathway
Chúng ta dùng Conv layer 1x1 để giảm số channel của C5 xuống 256-d để tạo ra M5. M5 là feature map đầu tiên được sử dụng cho object detection (cũng được gọi là P5).
Theo chiều mũi tên đi xuống của top-down pathway, chúng ta upsample layer phía trước M5 lên 2 lần bằng cách sử dụng nearest neighbors upsampling. Sau đó lại áp dụng Conv layer 1x1 cho feature map C4 rồi cộng chúng lại với nhau để nhận được feature map M4. Sau đó áp dụng Conv layer 3x3 cho M4 để nhận được P4 (việc này giúp giảm aliasing effect - hiệu ứng răng cưa khi kết hợp với upsampled layer từ M5).
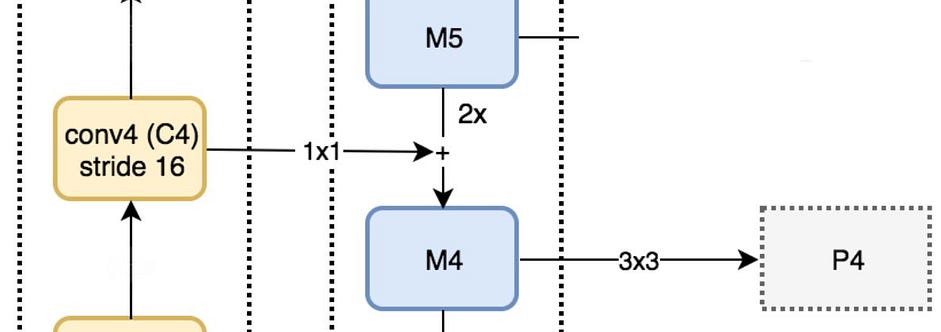
Chúng ta lặp lại quá trình này cho P3, P2. Chúng ta chỉ dừng lại ở P2 mà không tới P1 do spatial dimension của C1 quá lớn, điều này sẽ làm giảm tốc độ xử lý. Bởi vì chúng ta chia sẻ cùng classifier và box regressor cho mỗi output feature maps, do đó tất cả pyramid feature maps (P5, P4, P3, P2) đều có 256-d channels.
FPN with RPN (Region Proposal Network)
Chú ý: bản thân FPN không phải là object detector. FPN là feature extractor, nó hoạt động cùng với object detector.
FPN trích xuất đặc trưng sau đó đưa vào detector cho object detection. RPN áp dụng sliding window trên feature map để thực hiện prediction (có vật thể hay không có) và object boundary bounding box tại mỗi vị trí (trong Faster R-CNN có sử dụng anchor boxes).
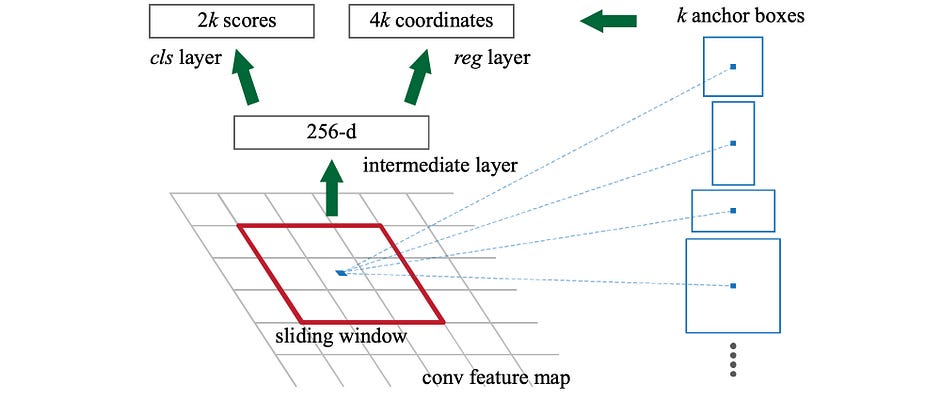
Trong FPN, ở mỗi scale level (ví dụ P4) lại áp dụng Conv layer 3x3, sau đó là Conv layer 1x1 để thực hiện objectness prediction và bounding box regression. Conv layer 3x3 và 1x1 được gọi là FPN head. Các predictor head cũng được áp dụng cho tất cả các scale của feature maps (từ P2 đến P5).
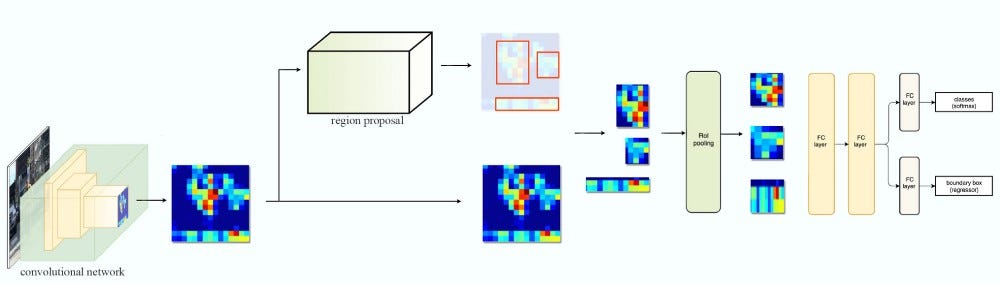
FPN with Fast R-CNN or Faster R-CNN
Cùng xem lại cách Fast R-CNN và Faster R-CNN làm việc: chúng sử dụng 1 feature map để tạo ra các ROIs. Sau đó sử dụng ROIs và feature map để tạo ra các feature patches (các mảng vá - một phần của feature map tương ứng vị trí của ROIs) để đưa vào ROI pooling, sau đó sẽ thực hiện object detection.
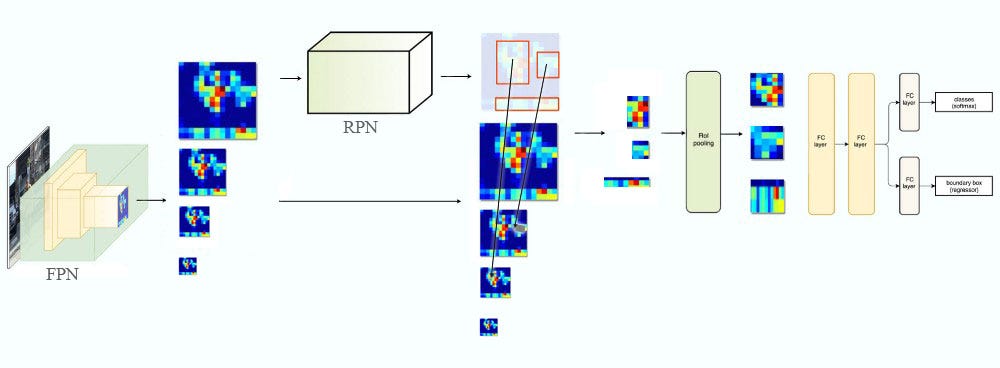
Trong FPN chúng ta tạo ra pyramid of feature maps. Sau đó chúng ta sẽ áp dụng RPN (region proposal network) để tạo ta các ROIs. Dựa trên kích thước của các ROI chúng ta sẽ chọn feature map layer phù hợp nhất về scale (tỉ lệ) để trích xuất các feature patches.
Công thức dưới đây giúp lấy feature map dựa trên width $w$ và height $h$ của ROI:
\[k=k_0+log_{2}\left ( \sqrt{wh}/224 \right )\]trong đó $k_0=4$ và $k$ là layer $P_k$ trong FPN được sử dụng để tạo feature patch.
Điều này có nghĩa rằng có thể xác định được feature map $P_k$ cần lấy khi có kích thước của ROI (kích thước này đã được rescale so với ảnh ban đầu đưa vào mạng).
Với $k=3$ chúng ta sẽ chọn P3 làm feature map. Sau đó chúng ta áp dụng ROI pooling và cho kết quả vào Fast R-CNN head (Fast R-CNN và Faster R-CNN có cùng head để thực hiện object detection).
Segmentation
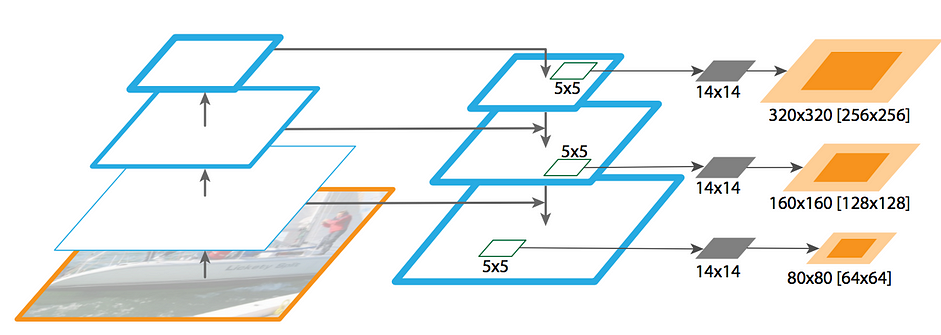
Cũng giống như Mask R-CNN, FPN cũng làm việc tốt khi trích xuất masks cho image segmentation. Bằng cách sử dụng MLP, window kích thước 5x5 trượt qua các feature map để tạo ra object segment với dimension 14x14. Sau đó kết hợp các masks với scale khác nhau (tỉ lệ) để hình thành final mask.
Results
Đặt FPN vào RPN cải thiện average recall (AR - khả năng phát hiện objects) rất nhiều.

Faster R-CNN dựa trên FPN cho kết quả khá tốt.

Một số bài học
Dưới đây là một số bài học rút ra được:
- Top-down pathway phục hồi lại resolution nhưng với rich semantic information
- Chúng ta cần lateral connection để xác định chính xác hơn vị trí của vật thể hơn
- Top-down pathway + lateral connection giúp cải thiện accuracy 8 điểm với COCO dataset. Đối với object nhỏ, nó cải thiện 12.9 điểm.
Tài liệu tham khảo
- https://jonathan-hui.medium.com/understanding-feature-pyramid-networks-for-object-detection-fpn-45b227b9106c
- https://towardsdatascience.com/review-fpn-feature-pyramid-network-object-detection-262fc7482610