
Multi-label classification
Nhóm mình đang có bài toán liên quan đến multi-label classification. Do đó mình viết bài này để chia sẻ một số vấn đề xung quanh multi-label classification.
1. Multi-label classification khác gì multi-class classification
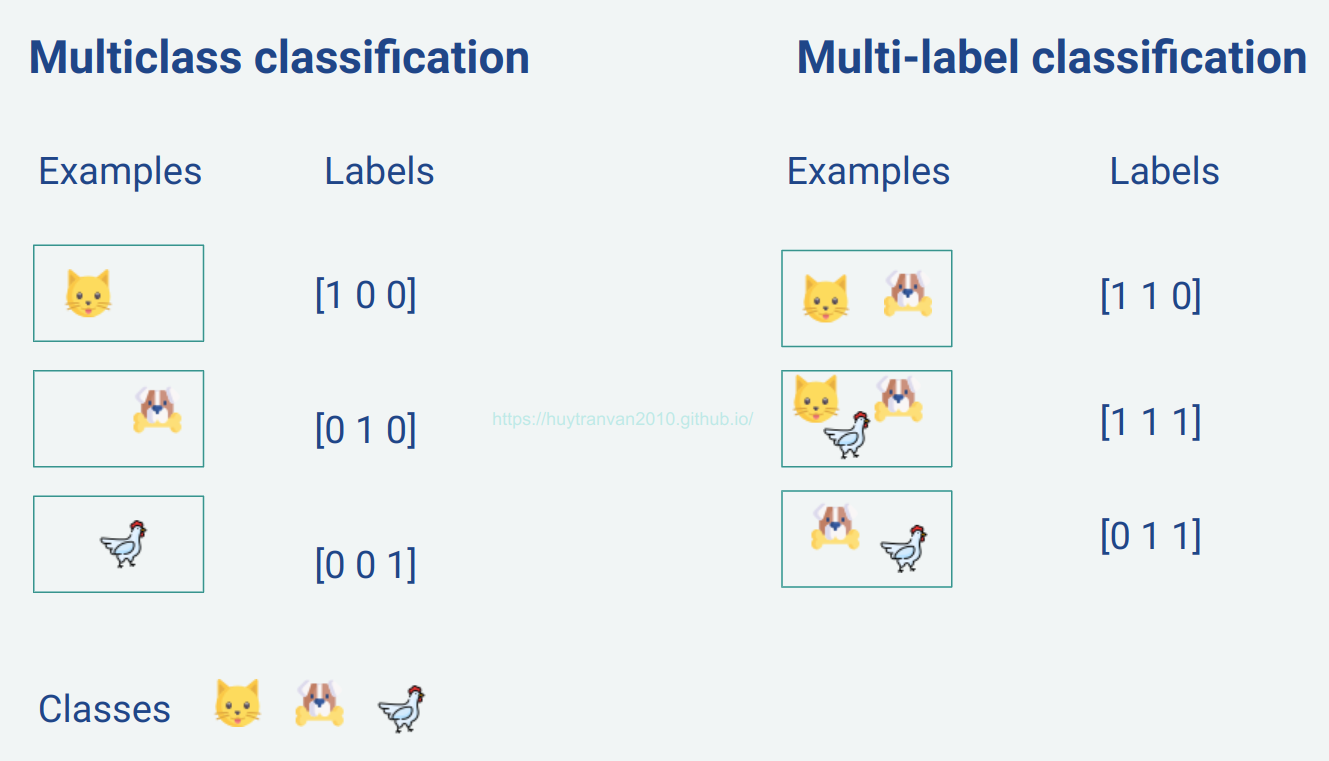
Chắc mọi người đã quen với bài toán multi-class classification như phân loại chữ số viết tay MNIST chẳng hạn. Trong bài toán này mỗi ảnh sẽ chứa duy nhất một class từ 0 đến 9 đại diện cho các chữ số. Số units của output layer sẽ bằng với số classes muốn phân loại. Thường sẽ áp dụng softmax activation function cho output layer.
Trong khi đó, bài toán multi-label classification, mỗi dữ liệu có thể chứa nhiều class. Ví dụ đối với dữ liệu ảnh chẳng hạn, ảnh có thể được gán nhãn vừa chứa chó vừa chứa mèo. Số units của output layer bằng với số classes có thể chứa trong mỗi ảnh. Thường chúng ta sẽ dùng sigmoid activation function cho output layer.
2. Một số kỹ thuật để giải quyết bài toán Multi-label classification
- Problem Transformation
- Adapted Algorithm
- Ensemble approaches
- Neural Network
2.1. Problem Transformation
Với phương pháp này chúng ta cố gắng chuyển đổi multi-label problem về single-label problem. Phương pháp này có thể thực hiện qua một số cách sau:
- Binary Relevance
- Classifier Chains
- Label Powerset
2.1.1. Binary Relevance
Đây là kỹ thuật đơn giản nhất, chúng ta sẽ xử lý các label một cách riêng rẽ. Cùng xem ví dụ dưới đây

Với binary relevance, chúng ta sẽ bài toán trên chia thành 3 single class classification (do ở đây có 3 classes). Từ đây có thể dễ dàng xử lý các bài toán riêng lẻ, sau đó kết quả cuối cùng có thể gộp lại làm một.
Thư viện Scikit-multilearn có hỗ trợ chúng ta trong việc này, vừa chia vừa train model luôn
from skmultilearn.problem_transform import BinaryRelevance
from sklearn.svm import SVC
# initialize Binary Relevance multi-label classifier
# with an SVM classifier
# SVM in scikit only supports the X matrix in sparse representation
classifier = BinaryRelevance(
classifier = SVC(),
require_dense = [False, True]
)
# train
classifier.fit(X_train, y_train)
# predict
predictions = classifier.predict(X_test)
2.1.2. Classifier Chains - chuỗi classifier
Ban đầu chúng ta có dataset như này

Trong classifier chains chúng ta cũng có 3 single label problem tương ứng với 3 classes.

- Classifier 1 có features là $\mathbf{X}$ và target là $\mathbf{y}_1$
- Classifier 2 có features là $\mathbf{X}$, $\mathbf{y}_1$ và target là $\mathbf{y}_2$
- Classifier 3 có features là $\mathbf{X}$, $\mathbf{y}_1$, $\mathbf{y}_2$ và target là $\mathbf{y}_3$
Cách này giúp giữ lại tương quan giữa các class (hiểu đơn giản như class này xuất hiện thì nhiều khả năng class kia sẽ xuất hiện). Chúng ta hoàn toàn có thể train các models riêng rẽ được.
Scikit-multilearn cũng hỗ trợ phương pháp này.
from skmultilearn.problem_transform import ClassifierChain
from sklearn.svm import SVC
# initialize Classifier Chain multi-label classifier
# with an SVM classifier
# SVM in scikit only supports the X matrix in sparse representation
classifier = ClassifierChain(
classifier = SVC(),
require_dense = [False, True]
)
# train
classifier.fit(X_train, y_train)
# predict
predictions = classifier.predict(X_test)
2.1.3. Label Powerset
Ý tưởng của label powerset là chọn ra các “class” duy nhất trong trong nhãn dữ liệu ban đầu.

Như hình trên, điểm dữ liệu x2 và x3 được coi có cùng nhãn, x4 và x6 được coi có cùng nhãn. x1 có nhãn riêng, x5 có nhãn riêng. Tổng cộng lúc này chúng ta có 4 classes mới cho model mới. Model này phục vụ cho bài toàn multi-class classification. Nhận thấy bài toán multi-label classification đã chuyển về bài toán multi-class classification.
Chú ý:
- Cần xử lý trường hợp trong test data có dữ liệu không thuộc nhãn nào ở training data. Lúc này chúng ta có thể tạo thêm một class mới - KHÔNG THUỘC CÁC CLASS TRÊN.
- Nếu có ban đầu $n$ classes thì chúng ta sẽ có tối đa $2^n$ classes cho bài toán multi-class classificationn
Trong Scikit-learn có hỗ trợ phương pháp này
from skmultilearn.problem_transform import LabelPowerset
from sklearn.ensemble import RandomForestClassifier
# initialize LabelPowerset multi-label classifier with a RandomForest
classifier = ClassifierChain(
classifier = RandomForestClassifier(n_estimators=100),
require_dense = [False, True]
)
# train
classifier.fit(X_train, y_train)
# predict
predictions = classifier.predict(X_test)
2.2. Adapted Algorithm
Đúng như cái tên, Adapted Algorithm sẽ điều chỉnh để algorithm để giải quyết trước tiếp multi-label classification thay vì chuyển thành các bài toán khác.
Ví dụ phiên bản multi-label của kNN được gọi là MLkNN.
from skmultilearn.adapt import MLkNN
classifier = MLkNN(k=20)
# train
classifier.fit(X_train, y_train)
# predict
predictions = classifier.predict(X_test)
accuracy_score(y_test,predictions)
2.3. Ensemble Appoaches
Emsemble method thường cho kết quả tốt hơn. Thư viện Scikit-Multilearn cung cấp nhiều ensemble classification functions, bạn có thể thử các hàm của nó.
2.4. Neural Network
Ở đây sẽ sử dụng mạng NN để giải quyết bài toán multi-label classification. Số units của output layer bằng với số classes quan tâm. Activation function được sử dụng là sigmoid còn loss function là binary crossentropy. Bên dưới sẽ có implementation cho bài toán multi-label classification.
3. Metrics cho multi-label classification
3.1. Example-based metrics
Example-based metrics là các metrics dựa trên các examples hay các samples, nó không đánh giá dựa trên từng classes.
3.1.1. Exact match ratio (EMR) - tỉ lệ khớp chính xác
\[acc = \frac{\text{số dự đoán đúng}}{\text{tổng số dự đoán}} = \frac{1}{n}\sum_{i=1}^{n}[\mathbf{I}(\mathbf{y}^{(i)} =\mathbf{\hat{y}}^{(i)}]\]trong đó, $n$ là số training examples $\mathbf{y}^{(i)}$ là true labels cho training example $i$ $\mathbf{\hat{y}}^{(i)}$ là prediction cho training example $i$ Exact match ratio được implement trong scikit-learn, các bạn có thể xem thêm tại đây.
Dữ liệu được coi là dự đoán đúng nếu prediction trùng với nhãn ban đầu. Ví dụ ảnh ban đầu chứa chó, mèo, cừu, khi dự đoán cũng chứa chó, mèo, cừu thì được coi là dự đoán đúng. Nếu dự đoán ảnh chỉ chứa chó, mèo thì là dự đoán sai.
EMR giúp chúng ta đánh giá tổng thể các classes, không phản ánh được đối với từng class riêng lẻ.
def emr(y_true, y_pred):
row_indicators = np.all(y_true == y_pred, axis = 1) # axis = 1 will check for equality along rows. y_true == y_pred trả về matrix chứa True, False, nếu tất cả các ptử trên một hàng là True thì trả về True cho hàng đó
exact_match_count = np.sum(row_indicators) # row_indicators contains only True or False
return exact_match_count/len(y_true)
3.1.2. Harming loss
Harming loss tính tỉ lệ các labels dự đoán không chính xác trên tổng số labels.
\[\text{Harming loss} = \frac{1}{nL}\sum_{i=1}^{n} \sum_{j=1}^{L}I(y^{(i)}_j \neq \hat{y}^{(i)}_j )\]trong đó:
- $n$ - số training examples
- $y^{(i)}_j$ là true labels cho training example $i$ và class $j$
- $\hat{y}^{(i)}_j$ là prediction cho training example $i$ và class $j$
- $L$ chính là số chiều của một label của dữ liệu
Harming loss cũng được implement trong Scikit learn.
Có thể implement như sau để so sánh với Scikit-learn:
def get_harming_loss(y_true, y_pred):
# incorrect labels
not_eq = np.sum(np.abs(y_true - y_pred))
return not_eq / (y_true.shape[0] * (y_true.shape[1])
Từ Harming loss chúng ta sẽ có Harming score.
3.1.3. Samples metrics
Chúng ta sẽ đi tính metrics cho mỗi sample sau đó sẽ đi lấy trung bình trên toàn bộ các samples.
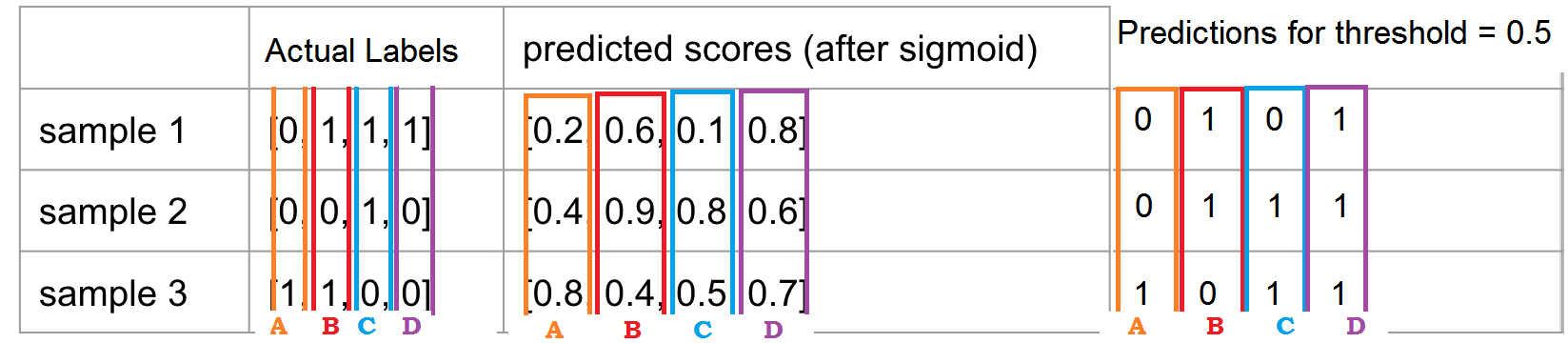
trong đó $n$ chính là tổng số examples trong dữ liệu.
total_Precision=0
# duyệt qua từng example hay sample
for i in range (len(y_true)):
# precision cho mỗi sample
p = metrics.precision_score(y_true[i,:], y_pred[i,:])
total_Precision += p
print("For Sample {} precision: {:.2f} ".format(y_true[i,:], p ))
print("Sample Precision: {:.2f}".format(total_Precision / len(y_true)))
Như hình trên chúng ta có true sample 1 là [0 1 1 1], dự đoán được là [0 1 0 1], từ đó sẽ đi tính các metrics thôi. Khá dễ hiểu phải không nào.
Việc xác định các đại lượng khác như recall cũng tương tự như vậy
3.2. Label-based metrics (các metrics dựa trên label)
Không giống với example-based metrics, label-based metrics được thực hiện cho mỗi class riêng rẽ, sau đó sẽ lấy trung bình trên tất cả các classes. Tất cả các metrics dùng cho binary classification đều có thể dùng được cho label-based metrics.
- Những metrics được tính trên class, sau đó mới lấy trung bình trên toàn bộ classes được gọi là macro-average
- Những metrics được tính trên toàn bộ các classes luôn được gọi là micro average.
- Tương tự như vậy cũng có weighted metrics (weight là số examples mà một class xuất hiện) và sample metrics.
Chúng ta cùng đi chi tiết vào các metrics để dễ hiểu hơn.
3.2.1. Macro-average
Macro-average accuracy
Công thức chung của accuracy
\[A = \frac{TP + TN}{\text{no of examples}}\] \[\text{Accuracy macro} = \frac{\sum_{j=1}^{k}A_{macro}^j}{k}\]trong đó $k$ - số classes. Đơn giản có thể lấy riêng dự đoán của từng class (tương ứng một cột trong ma trận true labels hay prediction) rồi xác định accuracy cho class đó.
Macro-average precision là trung bình cộng của các precision theo class. Nhớ lại công thức của precision:
\[Precison = \frac{TP}{TP + FP}\] \[\text{Precision macro} = \frac{\sum_{j=1}^{k}P_{macro}^j}{k}\]trong đó $k$ - số classes.
Đơn giản có thể lấy riêng dự đoán của từng class (tương ứng một cột trong ma trận true labels hay prediction) rồi xác định precision cho class đó.
total_Precision= 0
for i in range (len(label_names)):
# precison for each class
p = metrics.precision_score(y_true[:,i], y_pred[:,i])
total_Precision += p
print("For {} precision: {:.2f}".format(label_names[i], p))
print("Macro Precision: {:.2f}".format(total_Precision / len(label_names)))
Macro-average Recall
Nhớ lại công thức của Recall:
\[Recall = \frac{TP}{TP + FN}\] \[\text{Recall macro} = \frac{\sum_{j=1}^{k}R_{macro}^j}{k}\]Tương tự như trên, có thể lấy riêng dự đoán của từng class (tương ứng một cột trong ma trận true labels hay prediction) rồi xác định Recall cho class đó.
total_Recall = 0
for i in range (len(label_names)):
# precison for each class
r = metrics.recall_score(y_true[:,i], y_pred[:,i])
total_Recall += r
print("For {} recall: {:.2f}".format(label_names[i], p))
print("Macro recall: {:.2f}".format(total_Recall / len(label_names)))
Macro-average F-Score Macro-average F-Score được tính tương tự như F-score nhưng dựa trên macro-average precision và macro-average recall
Nhắc lại công thức tổng quát cho $F_\beta$ score:
\[F_{\beta} = ( 1 + \beta^2)\frac{\text{precision}\cdot\text{recall}}{\beta^2\cdot\text{precision} + \text{recall}}\]do đó
\[F_{\beta}^{\text{macro}} = ( 1 + \beta^2)\frac{\text{Precision\_macro}\times \text{Recall\_macro}}{\beta^2\cdot\text{Precision\_macro} + \text{Recall\_macro}}\]total_f1score = 0
for i in range (len(label_names)):
# precison for each class
f = metrics.f1_score(y_true[:,i], y_pred[:,i])
total_f1score += f
print("For {} F1 score: {:.2f}".format(label_names[i], p))
print("Macro F1 score: {:.2f}".format(total_f1score / len(label_names)))
Rõ ràng macro-average metric này không tính đến imbalance giữa các class. Ben dưới chúng ta sẽ giới thiệu weightes metric, nó sẽ tính đến imbalance của các classes.
3.2.2. Micro-average
Micro-average accuracy
Công thức tổng quát:
\[\text{micro-average accuracy} = \frac{\sum_{c=1}^C\text{TP}c}{\sum_{c=1}^C(\text{TP}c + \text{FP}c + \text{FN}c + \text{TN}c)}\]Nhìn lên công thức tính accracy cho từng class ở phần macro-average accuracy, ta thấy tử số và mẫu số của nó bây giờ được lấy tổng theo các classes giống như công thức tổng quát bên trên.
Micro-average precision
Công thức tổng quát:
\[\text{micro-average precision} = \frac{\sum_{c=1}^C\text{TP}c}{\sum_{c=1}^C(\text{TP}c + \text{FP}c)}\]Micro-average recall Công thức tổng quát:
\[\text{micro-average recall} = \frac{\sum_{c=1}^C\text{TP}c}{\sum_{c=1}^C(\text{TP}c + \text{FN}c)}\]Micro-average F-score cũng được tính dựa trên micro-average precision và micro-average recall.
Dưới đây là implementation cho các metrics trên
# reshape các labels về dạng vector cột (vẫn là 2d numpy array), ord="F" để lấy theo cọt trước
# mục đích để duỗi tất cả y^(i)_j ra. LÀm hết luôn
y_true = np.reshape(y_true, (y_true.shape[0]*y_true.shape[1], 1))
y_pred = np.reshape(y_pred, (y_true.shape[0]*y_pred.shape[1], 1))
TP = ((y_true + y_pred) == 1).sum()
FP = ((y_true - y_pred) == -1).sum()
TN = ((y_true + y_pred) == 0).sum()
FN = ((y_true - y_pred) == 1).sum()
micro_acc = (TP + TN) / (TP + FP + TN + FN)
micro_precison = TP / (TP + FP)
micro_recall = TP / (TP + FN)
micro_f1score = micro_precision * micro_recall / (micro_precision + micro_recall)
Những metrics macro, micro, average, samples có thể được xác định thông qua classification_report của thư viện scikit-learn.
3.3.3. Weighted
Chúng ta sẽ đi xác định metric cho từng label sau đi lấy trung bình có trọng số của các metric đó để được weighted metric. Trong số cho mỗi label chính là số examples chứa labels đó trong data ban đầu.
Weighted metric này khá giống với macro-average, chỉ có điều trong macro-average chúng ta coi các labels có weights như nhau. Việc có tính thêm weights của mỗi label giúp chúng ta tính đến imbalance trong dataset.
Cho accuracy:
\[\text{Weighted accuracy} = \frac{\sum_{j=1}^{k} n^j \times A^j}{\sum_{j=1}^{k} n^j}\]trong đó $k$ - số classes, $n^j$ là số examples có chứa class $\text{j-th}$.
Cho precision:
\[\text{Weighted precision} = \frac{\sum_{j=1}^{k} n^j \times P^j} {\sum_{j=1}^{k} n^j}\]Tương tự chúng ta cũng có cho Recall và từ đó xác định được F1-score.
Implementation cho weighted precision:
total_Precision = 0
total_examples=0
for i in range (len(label_names)):
p = metrics.precision_score(y_true[:,i], y_pred[:,i])
# số true examples của class i, nghĩa là số examples xuất hiện class i
no_ex = (y_true[:, i] == 1).sum()
# xác định tổng số examples
total_examples += no_ex
total_Precision += p * no_ex
print("For {} precision: {:.2f} support: {}".format(label_names[i], p, no_ex))
print("Weighted Precision: {:.2f}".format(totalPrecision / total_examples))
Trong scikit-learn đã implement cho chúng ta rồi, có thể kiểm tra chéo bằng cách in ra classification report như sau:
print(classification_report(y_true, y_pred,target_names=label_names))
4. Example
Dưới đây là implementation một model đơn giản cho bài toán multi-label classification.
Tạo dataset từ scikit-learn.
X, y = make_multilabel_classification(n_samples=1000, n_features=10, n_classes=3, n_labels=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Tạo model với 1 hidden layer.
model = Sequential()
model.add(Dense(20, input_dim=n_features, activation='relu'))
model.add(Dense(n_classes, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam')
Thực hiện training model
X_train, X_test, y_train, y_test = get_data()
n_features = X_train.shape[1]
n_classes = y_train.shape[1]
model = create_model(n_features, n_classes)
hist = model.fit(X_train, y_train, validation_data=(X_test, y_test), verbose=1, epochs=100)
4. Kết luận
Như vậy chúng ta đã tìm hiểu một số khía cạnh của bài toán multi-label classification. Các nội dung chính mình đã đề cập là:
- Multi-label classification
- Các phương pháp giải quyết bài toán:
- Problem Transformation
- Adapted Algorithm
- Ensemble approaches
- Neural Network
- Các metrics đánh giá model
Hy vọng mọi người tìm thấy điều gì đó hữu ích từ bài viết này.
5. Tài liệu tham khảo
- https://towardsdatascience.com/journey-to-the-center-of-multi-label-classification-384c40229bff
- https://machinelearningmastery.com/multi-label-classification-with-deep-learning/
- https://medium.datadriveninvestor.com/a-survey-of-evaluation-metrics-for-multilabel-classification-bb16e8cd41cd
- https://vnopenai.github.io/ai-doctor/vision/lung-abnormalities-classification-xray/models-and-experiments/
- https://www.analyticsvidhya.com/blog/2017/08/introduction-to-multi-label-classification/
- https://www.kaggle.com/kmkarakaya/multi-label-model-evaluation
- https://scikit-learn.org/stable/
- https://xang1234.github.io/multi-label/