
R-CNN Understanding
Giới thiệu
Năm 2014 Ross Girshick và các cộng sự đã đề xuất phương pháp mới cho object detection - R-CNN. Sau nay nó đã trở thành nền tảng cho các phương pháp như Fast R-CNN, Faster R-CNN và Mask R-CNN. Gần đây FAIR (Facebook AI Research) đã phát triển fully functional framework gọi là Detectron2 được xây dựng dựa trên các model state-of-the-art Faster R-CNN và Mask R-CNN.
Object detection
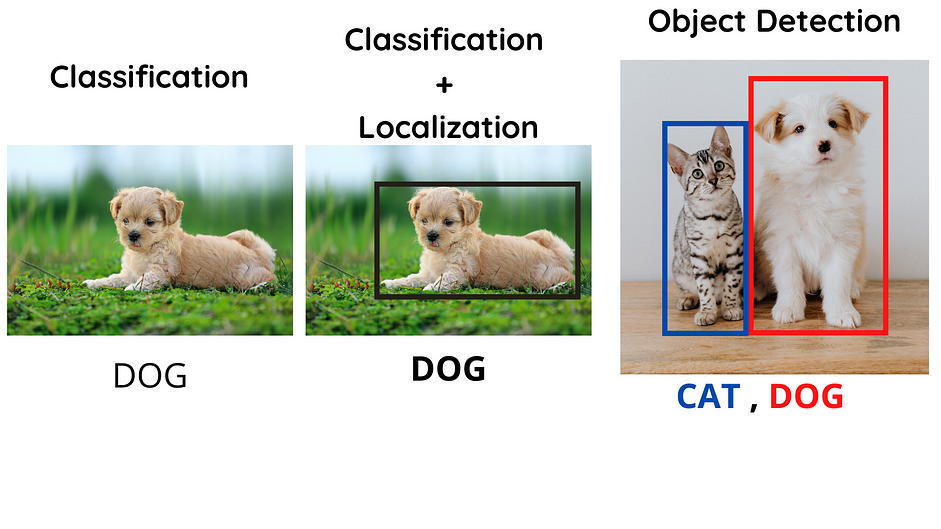
Nhớ lại một chút về các bài toán:
- Classification là đi xác định trong ảnh có vật thể gì
- Localization là đi xác định vị trí của vật thể đó trong ảnh (ở đây ám chỉ có 1 vật thể).
Tuy nhiên đối với bài toán object detection trong ảnh có thể có nhiều vật thể, chúng ta vừa phải xác định các vật thể đó là gì và vị trí của chúng ở đâu. Object detection bao hàm cả classification và localization.
Trước khi R-CNN xuất hiện, để giải quyết các bài toán object detection thời bấy giờ có các phương pháp như Sliding window + Image Pyramid hay họ Deformable Part Model…

Kỹ thuật Sliding window
Do các objects trong ảnh có nhiều kích thước khác nhau, do đó muốn phát hiện vật thể với nhiều kích thước khác nhau ta có thể thực hiện một trong hai cách sau:
- Giữ nguyên kích thước window, thay đổi kích thước ảnh
- Giữ nguyên kích thước ảnh, thay đổi kích thước window
Dưới đây thể hiện việc thay đổi kích thước ảnh (chúng ta có Image Pyramid) và giữ nguyên kích thước window. Khi đó vật thể lớn sẽ được phát hiện trong ảnh có kích thước nhỏ (vì lúc này kích thước ảnh thu lại), vật thể nhỏ sẽ được phát hiện trong ảnh có kích thước lớn.
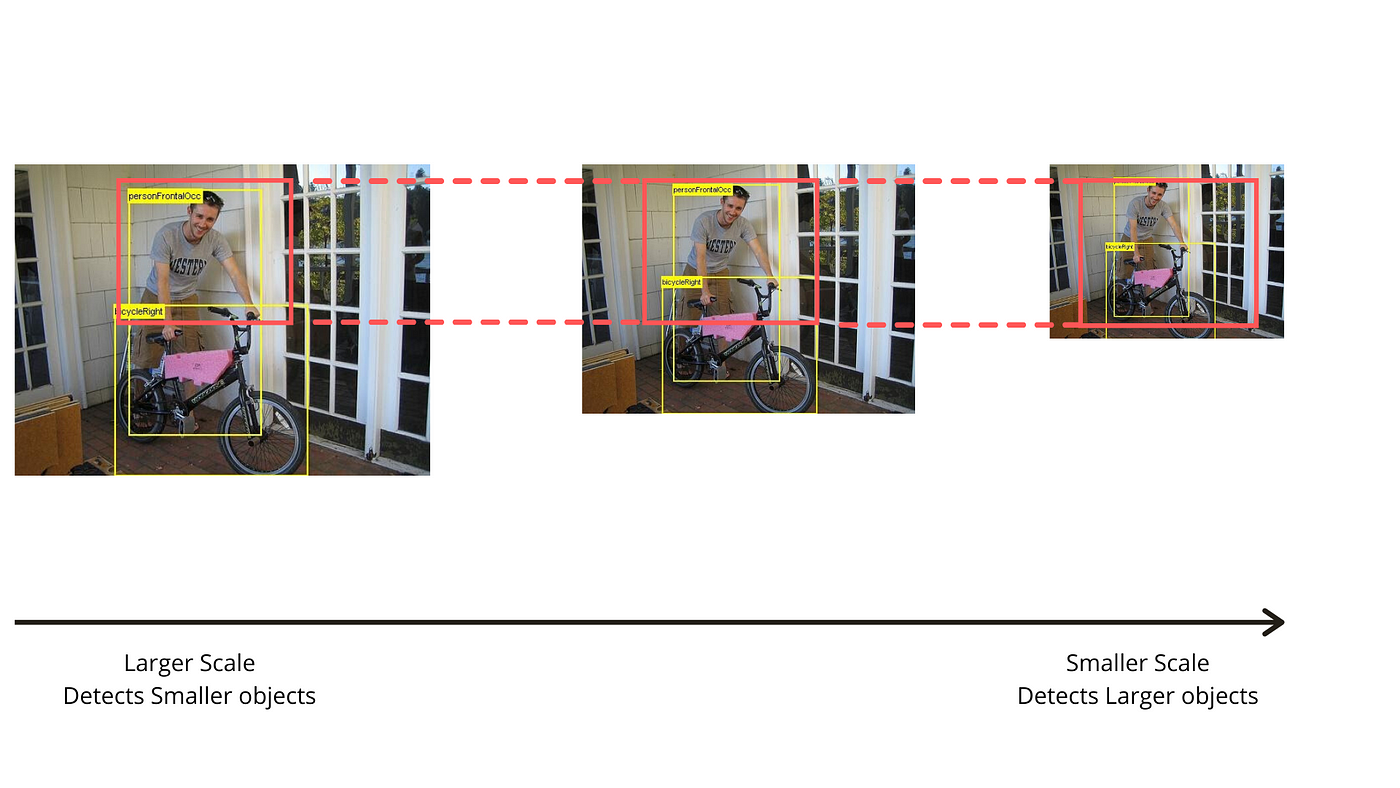
Thay đổi scale của image để phát hiện các vật thể
Tuy nhiên phương pháp Sliding Window + Image Pyramid có thể tạo ra một số lượng windows cực kỳ lớn khiến gian training và inference chậm.
Để giải quyết vấn đề đó thì Region proposal algorithms đã ra đời. Có một số phương pháp để tạo ra các region proposals như Selective Search, Colour Contrast, Edge Boxes, Super Pixel Straddling… Trong số chúng thì Selective Search và Edge Boxes hiệu quả hơn. Selective Search còn được gọi là Class-agnostic detector.
Class-agnostic detectors are often used as a pre-processor to produce a bunch of interesting bounding boxes that have a high chance of containing a cat, dog, car, etc.
Ở đây mình xin tóm tắt các bước của selective search để tạo ra các region proposals:
- Tạo sub-segmentation ban đầu, lúc này chúng ta có nhiều candiate regions
- Sử dụng greedy algorithm (thuật toán tham lam) kết hợp các vùng tương đồng nhau dựa vào color similarity, texture similarity, size similarity, meta similarity.
- Tạo các các region proposals cuối cùng có khả năng chứa vật thể

Mình có một bài về Selective search trong OpenCV, các bạn có thể xem tại đây.
R-CNN
R-CNN ở thời điểm ra mắt cho kết quả vượt trội so với các phương pháp object detection thời bấy giờ. R-CNN đạt được mAP 53.3% trên bộ dataset VOC 2012. Cái tên R-CNN bắt nguồn từ các kỹ thuật được sử dụng trong phương pháp này đó là :
- Region proposals
- CNN
Trong bài báo gốc tác giả sử dụng mô hình CNN AlexNet (chiến thắng trong cuộc thi năm 2012 phân loại trên bộ dữ liệu ImageNet). Tác giả cũng so sánh performance khi dùng các backbone khác nhau. Đến thời điểm hiện tại nếu dùng các pre-trained mới hơn như ResNet chẳng hạn, performance có thể được nâng lên.
Dưới đây là mô hình AlexNet.
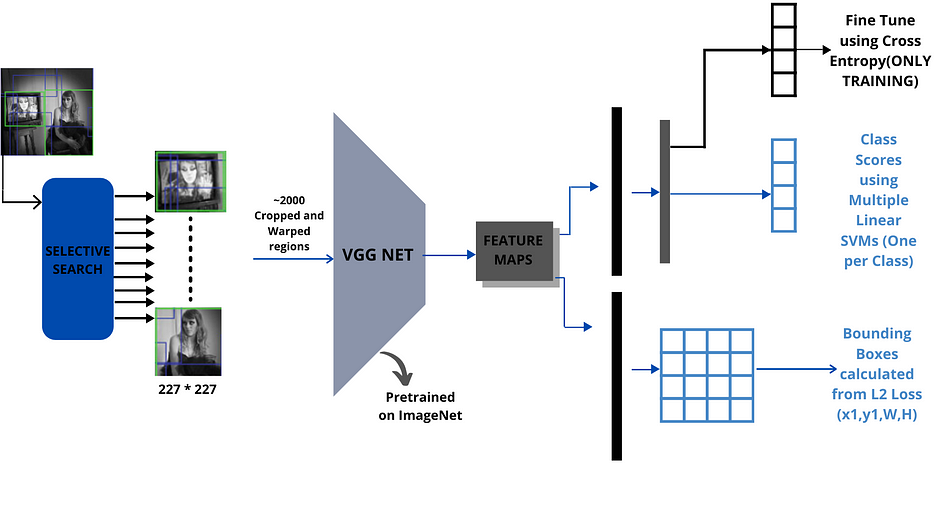
Chúng ta cùng xem các bước chung của mô hình R-CNN
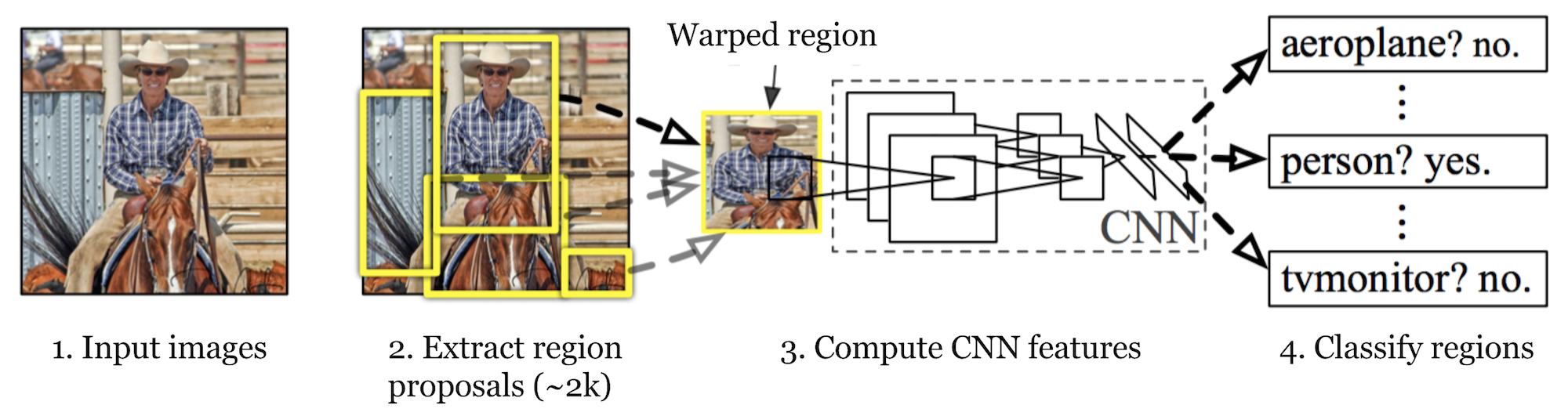
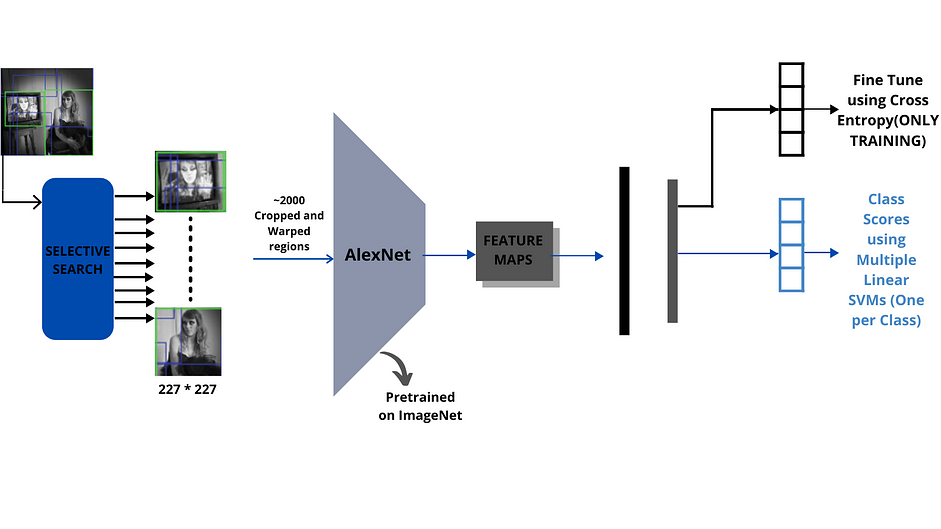
Ở đây chúng ta đi tìm hiểu các bước hoạt động chính của R-CNN trong quá trình training, khi inference thì đơn giản hơn nhiều (ở đây mình tập trung vào quá trình training): Bước 1. Download pre-trained model cho classification task, ví dụ các mô hình như AlexNet, ResNet… được train trên bộ dữ liệu ImageNet.
Bước 2. Dùng Selective search để tạo ra khoảng 2000 region proposals cho mỗi ảnh. Các vùng này có kích thước khác nhau, có thể chứa object hoặc không.
Bước 3. Các region proposals được resize lại về cùng kích thước cho phù hợp với mạng CNN (pre-trained CNN như AlexNet), thường là 224x224. Cuối cùng nhận được warped region.
Bước 4. Fine-tuning pre-trained CNN model dựa trên các warped regions cho $K+1$ classes. $K$ ở đây chính là số classes trong bộ object detection dataset. Cần cộng thêm 1 để tính đến background.
Việc Fine tuning này giúp cải thiện performance so với việc dùng trực tiếp pre-trained model do học được những đặc trưng riêng từ bộ dữ liệu ban đầu. Trong quá trình Fine tuning dùng SGD với learning rate nhỏ 0.001. Mỗi mini-batch lấy 32 positive examples và 96 negative examples (vì chủ yếu là background). Việc fine-tuning này chính là đi phân loại các positive và negative examples thuộc về $K+1$ classes. Positive example ở đây phải có $IoU \ge 0.5$ so với ground-truth box, còn lại được coi là negative examples.

Do các region proposals được chuyển về warped image để tương thích với đầu vào của backbone nên ảnh có bị biến dạng. Việc sử dụng luôn pre-trained CNN model trên warped imgaes cho kết quả không tốt nên đã thực hiện Fine tuning.
Bước 5. Train binary SVM cho mỗi class. Region proposals được đi qua CNN bên trên và trích xuất ra feature vector. Lưu tất cả feature vectors cho từng class. Sau đó sẽ train binary SVM classifier cho từng class độc lập với nhau. Ví dụ sau khi lưu feature vectors cho các proposals chúng ta sẽ có postive example cho class “CAT” và negative examples cho class “CAT”. Lúc này có thể train binary SVM classifier cho class “CAT”.
 Bước
Việc lấy positive và negative example cho từng class cho SVM như sau: positive chỉ là các ground-truth boxes của class đó, negative là các region proposals có IoU < 0.3 so với các instances của class đó. Những proposals có IoU > 0.3 so với các ground-truth của từng class bị bỏ qua.
Bước
Việc lấy positive và negative example cho từng class cho SVM như sau: positive chỉ là các ground-truth boxes của class đó, negative là các region proposals có IoU < 0.3 so với các instances của class đó. Những proposals có IoU > 0.3 so với các ground-truth của từng class bị bỏ qua.
Rõ ràng việc training này không thuộc kiểu end-to-end mà có sự gián đoạn từ CNN sang SVM. Đây cũng chính là nhược điểm của R-CNN.
Bước 6. Để tăng độ chính xác cho bounding box một mô hình, regession đã đào tạo được sử dụng để xác định 4 offset values. Ví dụ như khi region proposal chứa người nhưng chỉ có phần thân và nửa mặt người, nửa mặt người còn lại không có trong region proposal đó. Khi đó offset values có thể giúp mở rộng region proposal để lấy được toàn bộ người. Chúng ta thực hiện điều này do region proposals từ Selective Search không hoàn hảo hay không khớp hoàn toàn với ground-truth bounding boxes.
Trong R-CNN còn phân tích sự ảnh hưởng của việc dùng lớp FC 6 hay FC 7 lên performance của model với fine tuning và không có fine tuning. Phần này khá dài nên mình không viết ra ở đây.
Bounding Box Regression
Đầu vào cho regressor là cặp $(\textbf{p}_i, \textbf{g}_i)$ - $\textbf{p}_i$ có 4 giá trị tương ứng $p_x, p_y, p_w, p_h$ của region proposal (các tọa độ của tâm, width và height), $\textbf{g}_i$ cũng tương tự như vậy có $g_x, g_y, g_w, g_h$ cho ground-truth bounding boxes. (Cái này thực hiện sau SVM để biết thuộc class nào).
Regressor sẽ học scale-invariant transformation giữa 2 tâm và log-scale transformation giữa các width và height.
Chúng ta có thể tinh chỉnh vị trí của bounding box dựa trên các công thức sau. Nên nhớ $p_x, p_y, p_w, p_h$ là tọa độ tâm, width và height của region proposal đã biết. $d_x(\mathbf{p}), d_y(\mathbf{p}), d_w(\mathbf{p}), d_y(\mathbf{p})$ là những giá trị dự đoán được từ regression model. Và đối với dự đoán như này thì tọa độ tâm, width, height của vùng dự đoán có chứa vật thể là:
\[\begin{aligned} \hat{g}_x &= p_w d_x(\mathbf{p}) + p_x \\ \hat{g}_y &= p_h d_y(\mathbf{p}) + p_y \\ \hat{g}_w &= p_w \exp({d_w(\mathbf{p})}) \\ \hat{g}_h &= p_h \exp({d_h(\mathbf{p})}) \end{aligned}\]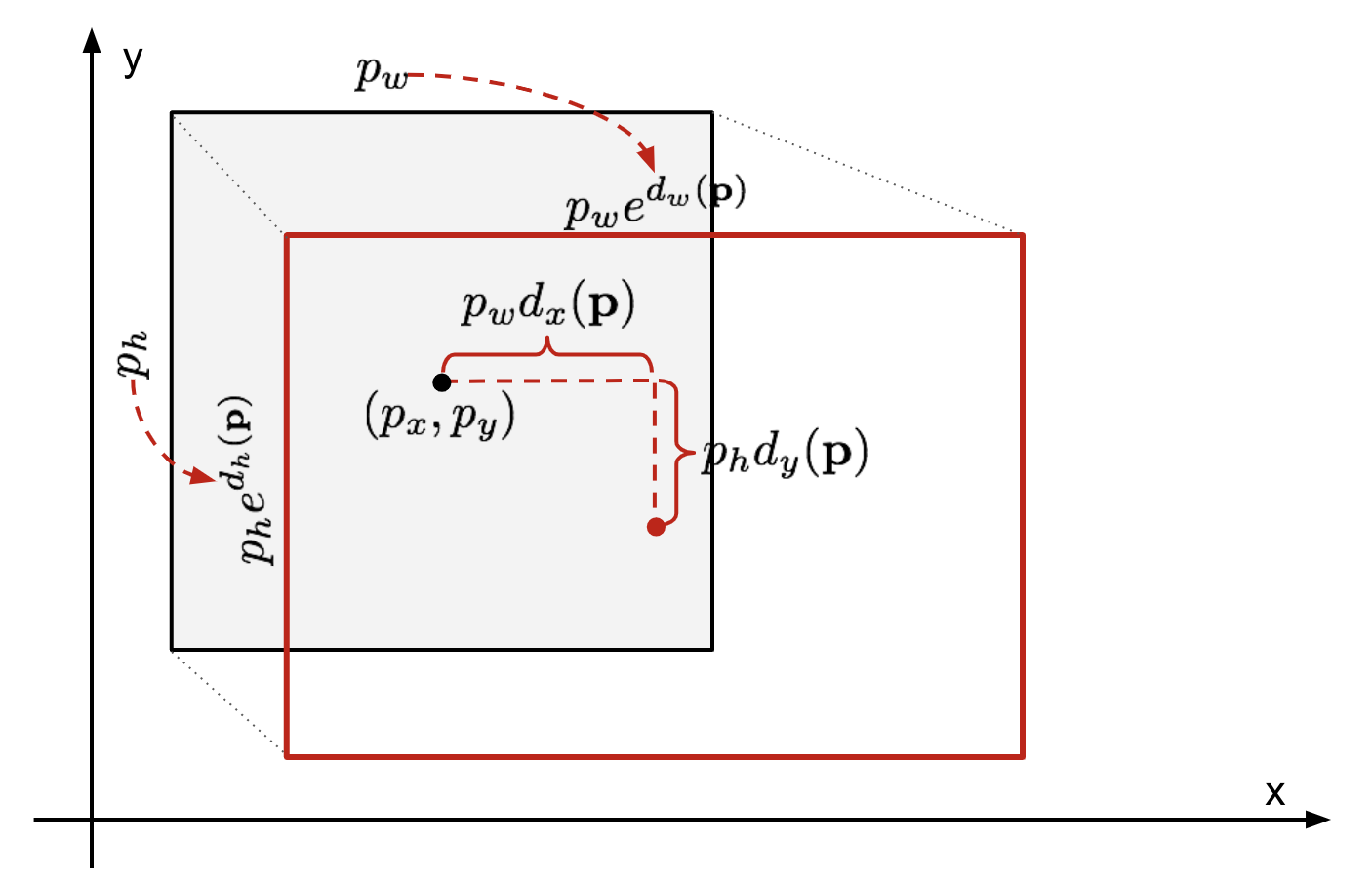
Chuyển đổi giữa ground-truth box và bounding box từ region proposal
Lợi ích của việc chuyển đổi này thay vì dùng giá trị tuyệt đối luôn vì $d_i(\mathbf{p})$ với $i \in { x, y, w, h }$ có thể nhận bất kỳ giá trị nào trong khoảng $(-\infty, +\infty)$ chúng ta cần thực hiện một số điều chỉnh để chặn giá trị trong khoảng cho phép.
Dưới đây chính là label ban đầu chúng ta có từ vị trí của ground-truth box và region proposal từ Selective Search:
\[\begin{aligned} t_x &= (g_x - p_x) / p_w \\ t_y &= (g_y - p_y) / p_h \\ t_w &= \log(g_w/p_w) \\ t_h &= \log(g_h/p_h) \end{aligned}\]Nhìn công thức này chắc phần nào mọi người đã hiểu hơn. Ban đầu chúng ta có ground-truth box và box of the region proposal, do đó có thể xác định được các giá trị $t_x, t_y, t_w, t_h$. Nhiệm vụ của chúng ta đi xây dựng regression model cho 4 đại lượng này với đầu vào là feature vector của region proposal. Nếu $d_x, d_y, d_w, d_h$ dự đoán của regressor khớp với $t_x, t_y, t_w, t_h$ (true label - offsets của region proposal so với ground-truth box ban đầu) thì vị trí box dự đoán với ground-truth box trùng nhau.
Xây dựng loss cho các bài toán regression này:
\[\mathcal{L}_* = \sum_{i=\{1,N\}} (t_*^{i} - d_*^{i}(\mathbf{p}))^2 + \lambda \|\mathbf{w_*}\|^2\]Trong đó $*$ lần lượt là $x, y, w, h$. Ở đây loss tính riêng cho từng giá trị: 2 tọa độ tâm, width và height chứ không gộp chung lại.
Chú ý:
- Việc xác định các cặp $(\textbf{p}_i, \textbf{g}_i)$ cũng rất quan trọng, không phải cặp nào cũng được chọn. Nếu box of the region proposal mà quá xa ground-truth bounding box thì việc học sẽ rất khó chính xác và không có ý nghĩa nhiều lắm. Do đó cần chọn $\textbf{p}_i$ gần với $\textbf{g}_i$. Cụ thể ở đây $\textbf{p}_i$ được gán cho $\textbf{g}_i$ mà với $\textbf{p}_i$ đó nó có IoU cao nhất, IoU cũng phải lớn hơn 0.6 mới lấy. Các $\textbf{p}_i$ có IoU thấp hơn 0.6 không được sử dụng.
- Việc viết $(\textbf{p}_i, \textbf{g}_i)$ thể hiện region proposal và ground-truth box có 4 giá trị đặc trưng là tọa độ tâm, width và height
Một số kỹ thuật hay dùng trong object detection
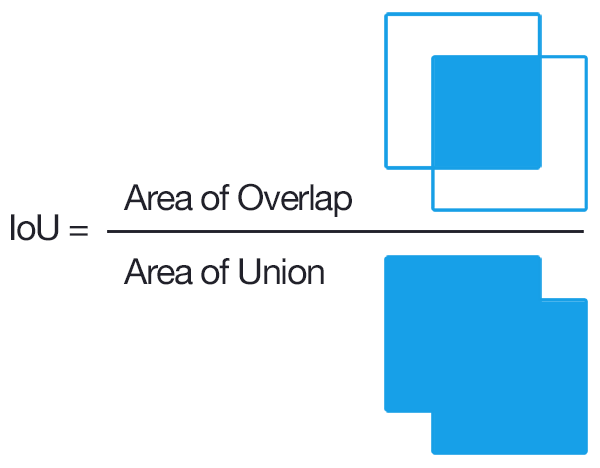
IoU - Intersection over Union
IoU được xử dụng trong bài toán object detection, để đánh giá xem bounding box dự đoán đối tượng khớp với ground truth thật của đối tượng. Nó cũng được sử dụng để loại bỏ bớt các bounding box cùng dự đoán cho một đối tượng. Chỉ số IoU:
- Có giá trị trong đoạn [0, 1]
- IoU càng gần 1 thì bounding box dự đoán càng gần ground-truth box
Non-max suppression
Một object có thể được phát hiện trong nhiều bounding box. Non-max suppression giúp chúng loại bỏ bớt các bounding box chỉ giữ lại duy nhất 1 cái cho mỗi object. Chúng ta có danh sách các bounding boxes cho một loại object:
- Sắp xếp các bounding boxes theo confidence score
- Loại bỏ các bounding boxes có confidence score nhỏ < min_score
- Chọn bounding box có confidence score lớn nhất. Sau đó loại bỏ các bounding boxes có IoU > 0.5 (ví dụ vậy) với bounding box vừa chọn ở trên.
- Lặp lại bước 3 cho đến hết.

Hard Negative Mining
Chúng ta coi các bounding boxes không chứa vật thể là negative examples. Tuy nhiên không phải tất cả negative examples đều khó nhận dạng như nhau. Ví dụ negative example chỉ chứa background được gọi là easy negative, những nếu box mà chứa một phần vật thể hoặc có họa tiết phức tạp nó có thể coi là hard negative.
Hard negative rất dễ bị phân loại sai (misclassified). Chúng ta có thể tìm đựợc các false positive samples (ảnh không chứa vật thể được dự đoán chứa vật thể) trong suốt quá trình training và đưa chúng vào training data để có thể cải thiện classifier.
Vấn đề của R-CNN
- Do lấy khoảng 2000 region proposals cho mỗi ảnh và phải train NN cho số region proposals đó nên thời gian train model rất lâu
- Vì lý do trên nên không thực hiện real-time được do thời gian xử lý cho mỗi test image cũng lâu (tùy thuộc vào cấu hình)
- Selective search có thể đưa ra những region proposals không được tốt.
- R-CNN không phải là mô hình end-to-end, nó bao gồm một số modules: CNN trích xuất feature, SVM để phân loại và regressor để tinh chỉnh bounding boxes. Ở đây không có sự chia sẻ tính toán.
Như vậy chúng ta đã tìm hiểu khá chi tiết về mô hình R-CNN. Chúng ta cũng đã nhận thấy mốt số vấn đề với R-CNN. Trong bài tiếp theo chúng ta sẽ đi tìm hiểu về mô hình Fast R-CNN một phiên bản cải tiến hơn của R-CNN.
Tài liệu tham khảo
- https://arxiv.org/abs/1311.2524
- https://learnopencv.com/selective-search-for-object-detection-cpp-python/
- https://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html
- https://towardsdatascience.com/understanding-object-detection-and-r-cnn-e39c16f37600
- https://towardsdatascience.com/understanding-fast-r-cnn-and-faster-r-cnn-for-object-detection-adbb55653d97
- https://github.com/huytranvan2010/RCNN-Understanding
- https://www.youtube.com/watch?v=o4AjHvl_yPg&list=PLANbacZNzD9HEbQ-CkACLyAqC3f0U9Plp&index=3
- https://www.youtube.com/watch?v=_GfPYLNQank&t=2481s