
U-Net
Trong bài toán object detection chúng ta chỉ cần xác định vị trí các bounding box và class của object. Tuy nhiên các bounding box bao quanh đối tượng, có thể bao luôn những phần không thuộc về đối tượng. Đối với các bài toán y tế hay xe tự hành việc xác định bounding box là chưa đáp ứng được yêu cầu, ví dụ phân tích ảnh y tế không những cần xác định vị trí mà còn cần xác định kích thước các khối u, vị trí bất thường. Đó chính là lý do đời của bài toán image segmentation, ta sẽ đi phân lớp các pixels trong ảnh.
Bài toán image segmentation được chia thành 2 loại:
- Semantic segmentation: thực hiện segment đối với các lớp khác nhau (chỉ phân biệt giữa các lớp). Một số ứng dụng của semantic segmentation:
- Xe tự hành: phân lớp pixels đối với xe, đường, người, biển báo… với mục đích xác định vị trí trống của đường…
- Trong y tế: segment các loại tế bào…
- Trong nông nghiệp: tránh lãng phí thuốc trừ sâu khi phun thuốc - phân đoạn ảnh với các lớp là cỏ dại và cây trồng (không phun vào cây trồng)
- Ảnh không gian: chụp ảnh từ không gian, có thể phân tách các vị trí nhà, đường, cơ sở quân sư. Cái này có thể ứng dụng trong lĩnh vực quân sự…
Một số kiến trúc hay được dùng để thực hiện semantic segmentation như U-Net…
- Instance segmentation: thực hiện segment đối với các đối tượng khác nhau (phân biệt giữa các đối tượng). Loại này có thể áp dụng để theo dõi hành vi của từng người. Có thể dùng Mask R-CNN để thực hiện segmentation.

U-Net
Mạng U-Net đầu tiên được ứng dụng trong lĩnh vực y sinh. Kiến trúc của mạng U-Net có 2 phần là encoder và decoder đối xứng nhau, hình dạng kiến trúc giống chữ U.
Trong kiến trúc U-Net có một layer mới là Transposed Convolution, khái niệm này chúng ta đã tìm hiểu rất rõ tại đây.
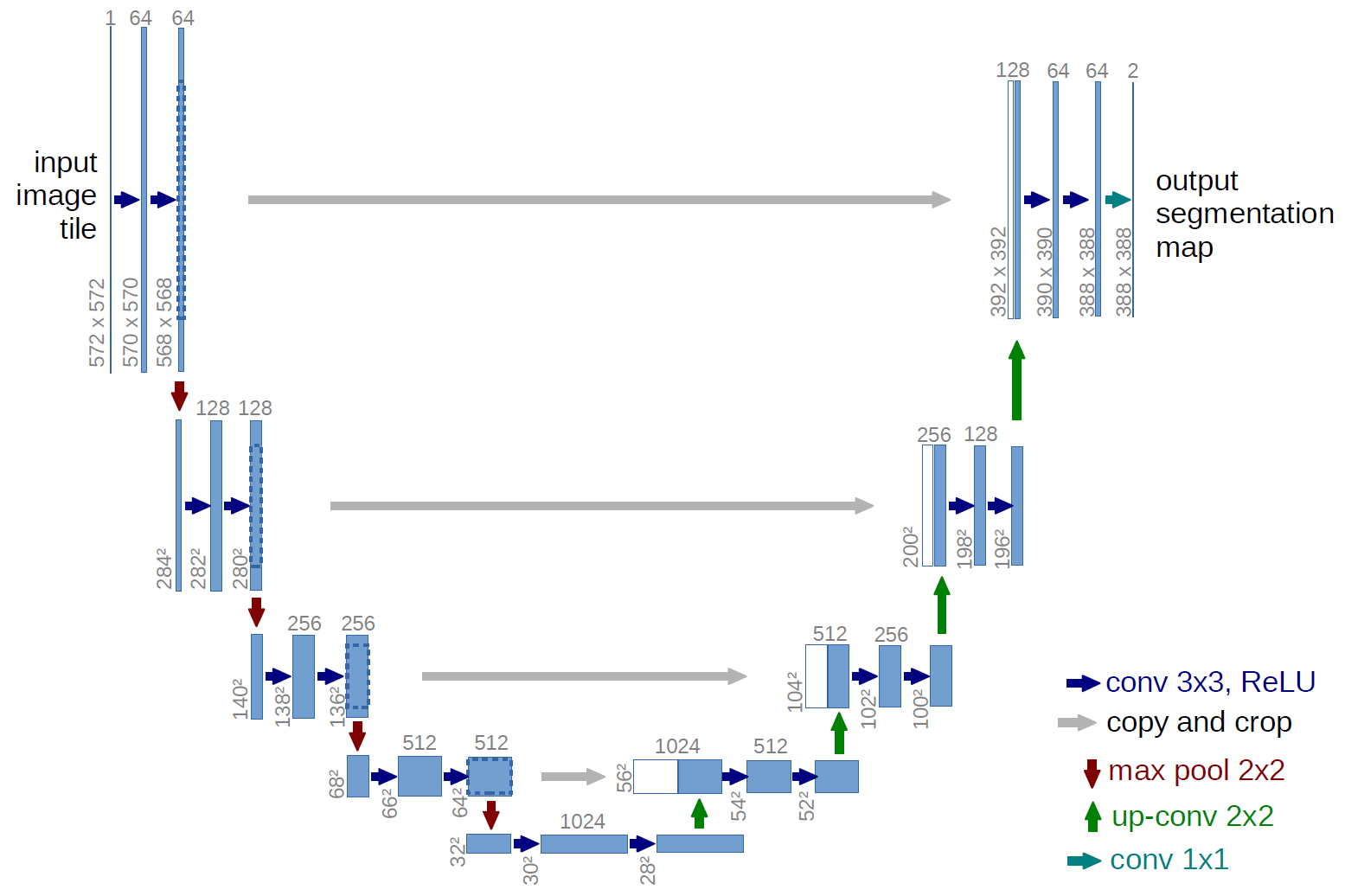
Kiến trúc mạng U-Net
- Mũi tên xanh lam chính là Conv layer
3x3, ReLU - Mũi tên xám là Skip connection (có crop)
- Mũi tên đỏ là Max Pooling
2x2 - Mũi tên xanh lá cây là Transposed convolution
- Mũi tên xanh ngọc là Conv layer
1x1 - Các số trên đỉnh hình chữ nhật chính là số channels của output
- Kích thước nằm dọc bên cạnh hình chữ nhật chính là kích thước là output
Nhận thấy kiến trúc U-Net không có lớp fully connected layer nào.
Encoder
Phần này bao gồm các Conv layers và MaxPooling thông thường. Đi từ trên xuống dưới width x height giảm, còn depth tăng. Depth của output mỗi layer được ghi ở trên đỉnh hình chữ nhật. width x height được ghi dọc theo hình chữ nhật.
Decoder
Phần này ngược lại với encoder, làm tăng width x height và giảm depth. Để làm được điều này cần áp dụng transposed convolution. Mỗi giai đoạn của decoder lại lấy layer phía đối xứng của encoder crop rồi concatenate lại (cách kết nối này tương tự với cách kết nối trong một số kiến trúc như ResNet hay DenseNet giúp cải thiện performance của model).
Nếu ảnh đầu vào của mình là ảnh màu kích thước $h \times w \times 3$ thì số channels đầu tiên là 3. Ở phần decoder chỗ áp dụng Conv layer 1x1, số filters chính là số classes mình cần segment, cái này tùy thuộc vào từng bài toán cụ thể. Output sẽ có dạng $h \times w \times \text{classes}$. Nếu lấy argmax theo chiều của channels chúng ta sẽ biết được từng pixel thuộc về class nào. Nhóm các pixel chung class vào một nhóm và gán màu cho chúng. Từ đây ta có thể tạo mask cho ảnh ban đầu với các phần segment của ảnh ban đầu.
Lý do sử dụng skip connection ở đây là nếu chỉ sử dụng feature map ở phía bên dưới để xây dựng lại feature map có spatial dimension cao hơn thì rất nhiều thông tin trên spatial dimension bị mất. Chính việc thêm skip connection ở phần encoder chúng ta sẽ tái tạo lại vị trí của các pixels tốt hơn.
Loss function
Đây là bài toán phân lớp cho các pixels nên loss function là tổng cross entropy của các pixels trong ảnh.
Mình còn đang viết tiếp nữa.
Tài liệu tham khảo
- https://towardsdatascience.com/understanding-semantic-segmentation-with-unet-6be4f42d4b47
- https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
- https://test.neurohive.io/en/popular-networks/u-net/
- https://www.coursera.org/learn/convolutional-neural-networks/home/week/3
- https://github.com/zhixuhao/unet
- https://lars76.github.io/2018/09/27/loss-functions-for-segmentation.html
- https://arxiv.org/abs/1505.04597