
Faster R-CNN
Trong hai bài trước chúng ta đã tìm hiểu về models R-CNN, Fast R-CNN và một số nhược điểm của chúng. Trong bài này hãy cùng tìm hiểu về model Faster R-CNN, một model mới hơn, cải thiện được nhược điểm của những người anh em trước đó.
Model Faster R-CNN được phát triển năm 2016 do Shaoqing Ren et al. Tương tự như Fast R-CNN, nó sử dụng mạng CNN để trích xuất feature map. Tuy nhiên thay vì sử dụng selective search để xác định region proposals thì Faster R-CNN sử dụng Region proposal network (RPN) để dự đoán các region proposals. Các predicted region proposals này được reshape lại bằng RoI pooling layer và được dùng để phân loại và xác định các giá trị offsets của bounding boxes.
Kiến trúc của Faster R-CNN có thể được miêu tả bằng hai mạng chính sau:
- Region proposal network (RPN) - Selective search được thay thế bằng ConvNet. RPN có hai outputs là: objectness score (object or no object) và box location
- Fast R-CNN - chứa các thành phần chủ yếu của Fast R-CNN:
- Base network cho feature extraction: thường là pretrained CNN model để có được feature map
- RoI pooling layer để có được fixed-size RoIs
- Output layer: chứa 2 FC layers cho softmax classifier và bounding box regression

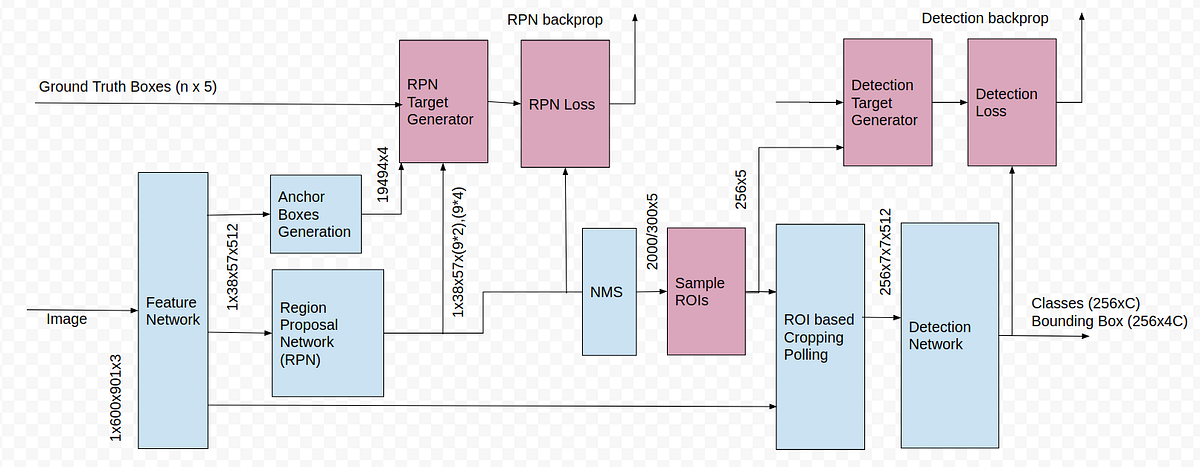
Như hình trên nhận thấy feature map vừa được đưa vào RPN xác định region proposals và được đưa vào RoI pooling layer để trích xuất fixed-size window of features.
Base network để trích xuất features
Tương tự Fast R-CNN, bước đầu tiên trong Faster R-CNN kà sử dụng pre-trained CNN model để trích xuất features từ input image. Ở đây có thể sử dụng nhiều pre-trained models được, trong bài báo tác giả sử dụng ZF và VGG trên ImageNet. Ngày nay có nhiều models cải tiến hơn được sử dụng làm backbone như ResNet, DenseNet…
Region proposal network (RPN)
RPN được train để trực tiếp đưa ra region proposals thay vì xác định region proposals dựa trên các method bên ngoài như Selective Search. Đầu vào của RPN là feature map từ ConvNet trước đó. RPN còn được biết với tên gọi attention network bởi vì nó hướng network tập trung vào các vùng quan tâm. Sau khi có region proposals thì chúng ta làm tương tự như Fast R-CNN đã làm.
Kiến trúc của RPN thường bao gồm 3 layers:
3x3fully convolutional layer (FCN) với 512 channels- Hai convolutional layers
1x1song song với nhau: classification layer được sử dụng để dự đoán region chứa object (có score tương ứng với background - không chứa object và foreground - chứa object. Nó chỉ quan tâm chứa object hay không) và layer cho regression hay bounding box prediction. Regression layer này giúp chúng ta có được các transformation parameters hay có được region proposals tốt hơn (khớp tốt với ground-truth boxes).

Convolutional implementation cho RPN architectur, k là tổng số achors cho một feature map
Chú ý: FCN có hai lợi ích chính:
- Tính toán nhanh hơn so với FC layer
- Có thể nhận image với bất kì spatial resolution (width và height). Tuy nhiên thông thường chúng ta thường cố định kích thước của input.
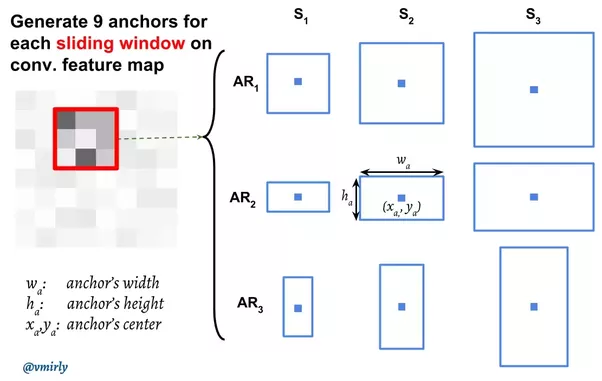
Thông thường vị trí của bounding box được xác định bởi $(x, y, w, h)$, trong đó $x, y$ là tọa độ tâm, $w$ là width và $h$ là height của bounding box. Tuy nhiên nếu xác định bounding box kiểu này thì khi xây dựng model chúng ta cần có một số giới hạn để các giá trị nằm trong khoảng cho phép. Để không phải làm điều đó, chúng ta đi tạo các anchor boxes, regression layer sẽ đi dự đoán offsets tính từ boxes này $(\Delta_x, \Delta_y, \Delta_w, \Delta_h)$, từ đó xác định được vị trí dự đoán cả region proposal đầu ra.
Anchor boxes
Bằng cách sử dụng window approach, RPN tạo ra $k$ regions cho mỗi vị trí trong feature map khi window trượt trên feature map. Các vùng này được gọi là anchor boxes. Cụ thể trong Faster R-CNN có 9 anchor boxes được định nghĩa với các kích thước 64x64, 128x128, 256x256 và các tỉ lệ khác nhau 1:1, 1:2 và 2:1. Tổng số lượng anchors sẽ phụ thuộc vào kích thước của feature map.
Mỗi vị trí của sliding window trên feature map sẽ tương ứng với một vị trí trên original image. Từ đó ta có thể xác định được ví trí của anchor boxes trên original image. Ở đây có phần ngược lại so với Fast R-CNN:
- Trong Fast R-CNN chúng ta xác định region proposals trên original image sau đó sẽ xác định vùng tương ứng của region proposals trên feature map
- Trong Faster R-CNN chúng ta xác định được vị trí của anchor boxes trên features (dựa vào vị trí của sliding window). Vị trí này trên feature map sẽ tương ứng với một vị trí trên original image thông qua subsampling ratio (tỉ lệ kích thước original image và feature map). Từ vị trí này và kích thước anchor boxes ta xác định được vùng tương ứng của anchor boxes trên original image. Có được vị trí thì dễ dàng xác định được transformation parameters giữa anchor boxes và ground-truth boxes, cái này được sử dụng làm label cho regression layer của RPN.

Tâm của anchor boxes trên original image
Dễ dàng nhận thấy khi chúng ta xác định được vị trí của anchor boxes tương ứng trên original image thì chúng ta cũng xác định được các transformation parameters của anchor boxes so với ground-truth boxes. Đây chính là labels cho regression layer của RPN.

Training RPN
RPN được train để phân loại anchor box, nó đưa ra objectnes score và các tọa độ xấp xỉ.
Các anchor boxes được gán nhãn positive hay foreground và negative hay background dựa trên IoU của nó với ground-truth bounding boxes:
- Các anchor có IoU lớn nhất với ground-truth box được coi là positive
- Các anchors có $IoU \ge 0.7$ được coi là positive
- Các anchors có $IoU < 0.3$ được coi là negative
- Các anchors có $0.3 < IoU < 0.7$ không được xếp vào hai loại kia và không được sử dụng trong quá trình training.
Chú ý: có điều kiện IoU lớn nhất làm positive để đảm bảo trường hợp các IoU nhỏ hơn 0.7 thì chúng ta vẫn có positive example.
Với 2 output layers, RPN đưa ra $2k$ scores và $4k$ coordinates, ở đây $k$ là tổng số lượng anchors trên một feature map. Ví dụ mỗi vị trí lấy 9 anchors, kích thước của feature map là $w \times h$, khi đó tổng số anchor boxes cho một feature map là $k= w \times h \times 9$.

Thông thường khi training mỗi lần chúng ta sẽ load mini-batch size các ảnh vào. Tuy nhiên đối với Faster R-CNN mỗi lần chúng ta chỉ sử dụng duy nhất một ảnh, và trong một ảnh này chúng ta sẽ lấy ra 256 anchors bao gồm 128 positive anchors và 128 negative anchors. Thông thường số lượng positve anchors nhỏ và có thể không đủ 128 cho một ảnh. Trong trường hợp đó chúng ta sẽ bổ sung thêm các negative anchors cho đủ 256 anchors.
RPN dùng tất cả anchors được chọn cho mini-batch để tính classification loss (binary cross entropy). Sau đó nó chỉ sử dụng những anchors trong mini-batch được đánh dấu là foreground (positive) để tính regression loss. Để xác định targets cho RPN regression chúng ta sử dụng foreground anchor và ground-truth box gần nó nhất để xác định transformation parameters.
Sau RPN chúng ta thu được region proposals, rất nhiều trong số chúng bị overlap với nhau nên cần có phương pháp để loại bỏ bớt các region proposals trước khi đưa nó vào phần sau. Ở đây sẽ dùng Non-max suppression (NMS):
- Bước 1: Ví dụ có tập hợp các RoIs thu được R với các confidence scores tương ứng S và overlap threshold N. Tạo list rỗng D
- Bước 2: Chọn RoI có confidence score lớn nhất, xóa khỏi R và cho vào D.
- Bước 3: So sánh IoU của RoI vừa được thêm vào D và các RoIs còn lại trong R với threshold IoU, nếu IoU > threshold IoU thì loại bỏ các RoIs đó khỏi R
- Bước 4: Lặp lại các bước 2 và 3 cho đến khi hết RoIs trong R. Các RoIs cuối cùng chúng ta nhận được là các RoIs trong list D.

Trong bài báo áp dụng IOU threshold bằng 0.7, sau đó giữ lấy top-N (N=2000) cho region proposals trước khi được nó đi tiếp vào RoI pooling layer.
Tuy nhiên thuật toán NMS ban đầu có một số nhược điểm, giả sử có threhsold IoU là 0.5:
- Ví dụ RoI có IoU = 0.51 nhưng có confidence score cao vẫn bị loại bỏ (ở bước 3)
- Có RoI có IoU < 0.5 nhưng có confidence score nhỏ vẫn được giữ lại (ở bước so sánh 3) .Chính những nhược điểm này làm cho chất lượng của model giảm xuống. Cần có phương pháp mới cải tiến NMS ban đầu này.
Multi-task loss function
Tương tự Fast-RCNN, Faster R-CNN được tối ưu dựa trên multi-task loss function:
\[L = L_{cls} + L_{loc}\] \[L(\{p_i\}, \{t_i\}) = \frac{1}{N_{cls}}\sum L_{cls}(p_i, p_i^{*}) + \frac{\lambda}{N_{loc}}\sum p_i^{*} \times L1_{smooth}(t_i - t_i^{*})\]trong đó:
- $p_i$ là predicted probability mà anchor $i$ chứa object và $p_i^{*}$ là binary ground truth (0 hoặc 1) anchor $i$ chứa object.
- $t_i$ là 4 predicted transformation parameters cái xác định bounding box, $t_i^{*}$ là các transformation parameters cho ground truth box và anchor box
- $N_{cls}$ - normalization term, được set cho mini-batch size 256 như vừa nói ở trên.
- $N_{loc}$ - normalization term, được set cho số anchors (~2400) theo bài báo.
- $L_{cls}(p_i, p_i^{*})$ - log loss function cho 2 classes. Chúng ta có thể dễ dàng chuyển multi-class classification thành binary classification bằng cách dự đoán xem sample có phải là object không.
- $L1_{smooth}$ - function đo lường sự khác nhau giữa predicted và true location parameters $(t_i, t_i^{*})$
- $\lambda$ - balancing parameter, bài báo set bằng 10, $\lambda$ thể hiện đóng góp của classification loss và regression loss.
Model workflow
- Pre-train a CNN network treên image classification tasks
- Fine-tune RPN cho region proposal task, cái này được khởi tạo bằng pre-train image classifier với các positive và negative examples như đã nói ở trên
- Train Fast R-CNN object detection model bằng cách sử dụng proposal được tạo ra từ RPN
- Sử dụng Fast R-CNN network để khởi tạo RPN training. Trong khi vẫn giữ việc chia sẻ convolutional layers, chỉ thực hiện fine-tune RPN-specific layers. Tại bước này, RPN và detection network đã chia sẻ convolutional layers.
- Fine-tune unique layers của Fast R-CNN
- Các bước 4-5 có thể lặp lại để train RPN và Fast R-CNN thay thế nhau nếu cần.
Ở trên các procedure trong bài báo gốc, sử dụng alternating optimization để train RPN, sau đó là Fast R-CNN dựa trên proposals từ RPN. Tuy nhiên các này khá phức tạp.
Chúng ta có thể kết hợp tất cả lại để có một mạng NN lớn hơn. Lúc này chúng ta sẽ có 4 losses:
- RPN classification (anchor good/bad hay có chứa object hay không)
- RPN regression (anchor box => proposal)
- Fast R-CNN classification (cho tất cả các classes)
- Fast R-CNN regression (proposal => box)
Chú ý:
- Từ vị trí của anchor boxes và ground-truth boxes chúng ta có labels cho RPN regressor layer - là các transformation parameters. Từ giá trị dự đoán này chúng ta xác định được vị trí của region proposals dựa trên vị trí của anchor boxes.
- Từ vị trí của region proposals xác định được ở trên, chúng ta có labels cho Fast R-CNN regressor - là các transformation từ proposals đến ground-truth box. Do đó khi inference, có các predicted values này + vị trí của proposals từ RPN (được xác định từ predicted values của regression layer RPN và vị trí của anchor boxes) chúng ta sẽ xác định định vị trí của predicted boundbing box.
Tài liệu tham khảo
- https://datascience.stackexchange.com/questions/27277/faster-rcnn-how-anchor-work-with-slider-in-rpn-layer
- https://youtu.be/_GfPYLNQank
- https://lilianweng.github.io/posts/2017-12-31-object-recognition-part-3/
- Deep Learning for Vision Systems
- http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
- https://www.youtube.com/watch?v=_GfPYLNQank&t=3193s
- https://tryolabs.com/blog/2018/01/18/faster-r-cnn-down-the-rabbit-hole-of-modern-object-detection