
EfficientNet Understanding
Từ khi mạng AlexNet chiến thắng trong cuộc thi ImageNet Challenge, Convolutional Neural Networks (CNN) trở nên phổ cập trong lĩnh vực Computer Vision. Mạng CNN cũng được áp dụng rất nhiều trong xử lý ngôn ngữ tự nhiên. Tuy nhiên một trong số các vấn đề thiết kế mạng CNN hay các mạng NN nói chung là model scaling (mở rộng mô hình) - tăng kích thước model như thế nào để tăng accuracy. Đây là một quá trình khá nhàm chán đòi hỏi thử đi thử lại nhiều lần để có được model với độ chính xác chấp nhận được và cũng phải thỏa mãn tài nguyên hệ thống. Quá trình này tốn thời gian, công sức và thường tạo ra model dưới mức tối ưu (chưa phải tối ưu nhất).
Năm 2019 nhóm nghiên cứu của Google đã phát hành bài báo liên quan tới họ CNN mới - EfficientNet. Mô hình CNN này không làm tăng accuracy mà còn cải thiện hiệu suất của model bằng cách giảm số parameters và FLOPS (Floating Point Operations Per Second) so với các mô hình hiện đại như GPipe. Những đóng góp chính của bài báo này bao gồm:
- Thiết kế simple mobile-size baseline architecture (kiến trúc cơ sở đơn giản kích thước di động):EfficientNet-B0
- Cung cấp phương pháp compound scaling (mở rộng kết hợp) một cách hiệu quả giúp tăng kích thước model để đạt được độ chính xác cao nhất.
EfficientNet-B0 Architecture
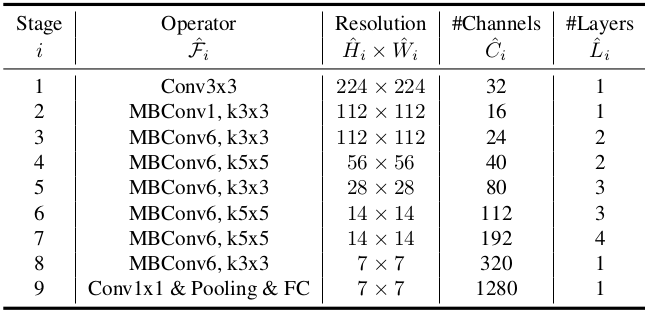
Kiến trúc chi tiết của mạng cơ sở
Phương pháp mở rộng kết hợp có thể tổng quát hóa các kiến trúc CNN có sẵn như MobileNet và ResNet. Tuy nhiên việc chọn base network (mạng cơ sở) là quan trọng để đạt được kết quả tốt nhất bởi vì phương pháp mở rộng kết hợp chỉ giúp tăng khả năng dự đoán của mạng NN bằng cách tái tạo lại các phép toán và cấu trúc của mạng cơ sở.
Trong bài báo tác giả cũng sử dụng Neurak Architecture Search để xây dựng kiến trúc mạng hiệu quả - EfficientNet B0. Kiến trúc này đạt 77.3% accuracy trên ImageNet với 5.3M parameters và 0.39B FLOPS (ResNet-50 đạt 76% accuracy với 26M parameters và 4.1B FLOPS).
Building block chính của EfficientNet-B0 là MBConv block. MBConv block tương tự như inverted residual block được sử dụng trong MobileNet v2. Trong block này có shortcut connection (kết nối tắt) giữa phần đầu và cuối của block. Phần input được mở rộng bằng Conv layer 1x1 để tăng số channels hay depth của feature map. Sau đó chúng ta sử dụng Depthwise convolution 3x3 và Pointwise convolution (Conv layer 1x1) để giảm số channels của output. Shortcut connection kết nối các narrow layers (layers hẹp - số channels nhỏ) trong khi các wider layers (layers rộng hơn) nằm ở giữa shortcut connection. Cấu trúc này giúp giảm số lượng parameters và số lượng operations tương ứng.
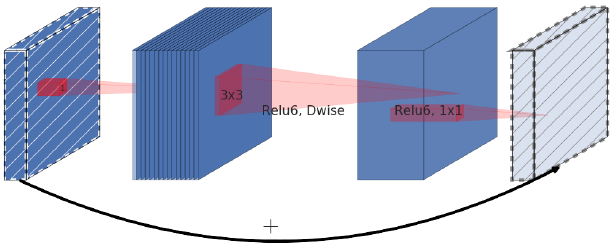
Inverted residual block
Chúng ta có thể xây dựng inverted residual block trong Tensorflow như sau:
import tensorflow as tf
def inverted_residual_block(x, expand=64, squeeze=16):
block = tf.keras.layers.Conv2D(expand, (1,1), activation=’relu’)(x) # expand layer
block = tf.keras.layers.DepthwiseConv2D((3,3), activation=’relu’)(block)
block = tf.keras.layers.Conv2D(squeeze, (1,1), activation=’relu’)(block) # squeeze layer, chỗ này có sử dụng non-linearly activation function
return tf.keras.layers.Add()([block, x])
Compound scaling (mở rộng kết hợp)
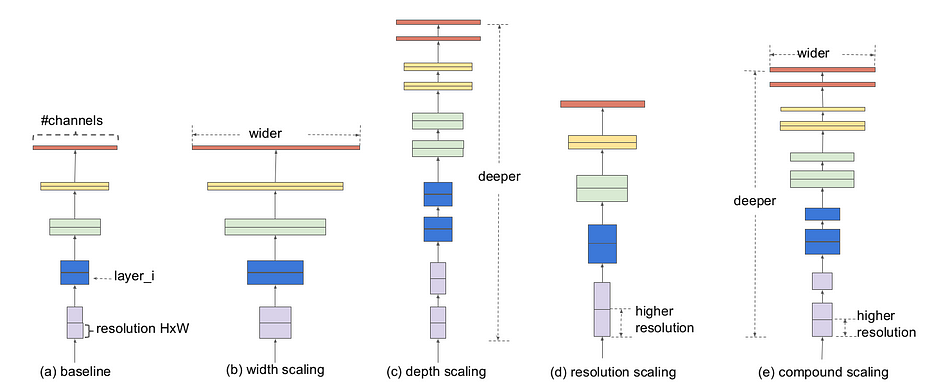
Model scaling. (a) - baseline network, (b)-(d) - scaling theo width, depth, resolution, (e) - compound scaling method that uniformly scales all three dimensions with a fixed ratio
Mạng CNN có thể được mở rộng theo 3 chiều: depth, width, resolution. Depth (độ sâu) của mạng NN tương ứng với số layers trong mạng. Width (độ rộng) liên quan đến số neurons trong mỗi layer hoặc số filters trong mỗi Conv layer (số channels của output). Resolution (độ phân giải) đơn giản là height và width của ảnh đầu vào.
Depth scaling
Scaling theo độ sâu là cách thường dùng để scale model. Depth có thể được tăng lên hoặc giảm đi bằng cách thêm hay giảm layers. Ví dụ ResNet=50 có thể được scale up lên ResNet-200 hay ResNet-50 có thể được scale down xuống ResNet-18.
Tăng độ sâu bằng cách xếp chồng nhiều Conv layers lên nhau cho phép mạng học được nhiều complex features. Tuy nhiêm mạng càng sâu sẽ càng phải chịu vanishing gradient và rất khó để train. Mặc dù các kỹ thuật như Batch Normalization hay skip connection rất hiệu quả để giải quyết vấn đề này nhưng các nghiên cứu thực tế cho thấy độ chính xác đạt được do tăng độ sâu sẽ nhanh chóng bị bão hòa. Ví dụ ResNet-1000 cho độ chính xác tương đường ResNet-100 mặc dù số layers của nó lớn hơn rất nhiều.
Width scaling
Tăng độ rộng của mạng NN giúp model học được các features chi tiết hơn (fine-grained features). Khái niệm này cũng được sử dụng nhiều trong các nghiên cứu như Wide ResNet và MobileNet. Tuy nhiên cũng giống như việc tăng độ sâu, tăng độ rộng ngăn cản mạng học complex features dẫn đến giảm accuracy.
Resolution scaling
Độ phân giải của ảnh đầu vào càng cao thì độ chi tiết của ảnh càng cao. Điều này có thể tăng khả năng của model trong việc suy luận phân tích về các object nhỏ hơn mà pattern chi tiết hơn. Tuy nhiên tăng độ phân giải thì accuracy gain diminishes very quickly. Ví dụ tăng độ phân giả từ 500x500 lên 560x560 không có cải thiện đáng kể về accuracy.
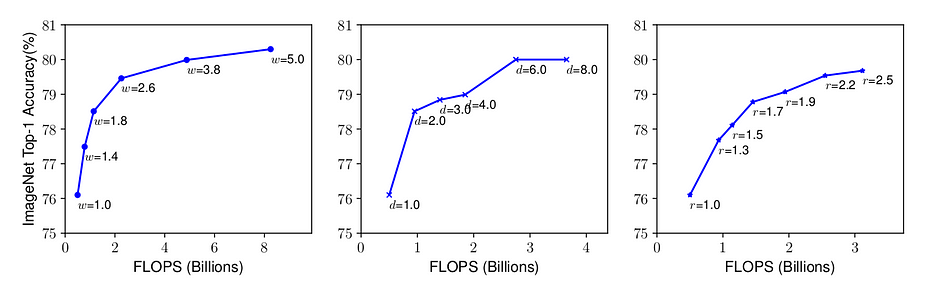
Scaling up a baseline model with different networkk width, depth and resolution coefficients
Chúng ta có một số quan sát sau:
- Quan sát 1 - mở rộng bất kỳ dimensions nào của network: width, depth, resolution đều cải thiện accuracy, tuy nhiên accuracy sẽ đạt tới bão hòa đối với các model lớn.
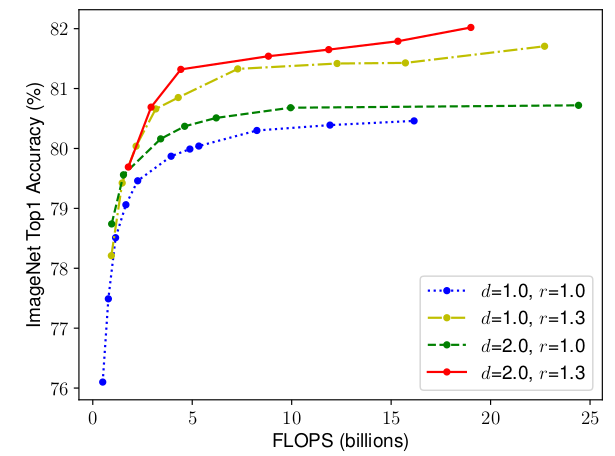
Scaling network width for different baseline networks
Điều này có ngụ ý rằng việc mở rộng mạng NN để tăng độ chính xác nên được đóng góp bởi sự kết hợp của 3 dimensions. Hình trên nhận thấy acccuracy của model ngày càng tăng với sự kết hợp của độ sâu và độ phân giải. Nếu chỉ mở rộng theo 1 chiều width thì accuracy nhanh chóng bị bão hòa lại (đường màu xanh lam).
Quan sát này có thể được giải thích như sau: nếu độ phân giải tăng lên, độ sâu và độ rộng của mạng NN cũng nên tăng lên. BỞi vì khi tăng độ sâu thì receptive field có thể nắm bắt được các similar features cái mà bao gồm nhiều pixels trong ảnh. Tương tự như vậy khi tăng độ rộng thì fine-grained features sẽ được học. Nhận thấy như hình trên với độ sâu lớn hơn và độ phân giải cao hơn, mở rộng theo chiều rộng sẽ đạt được accuracy tốt hơn với cungf FLOPS (kết hợp các dimensions). Điều này dẫn đến quan sát thứ hai:
- Quan sát 2 - để có được độ chính xác và hiệu suất tốt hơn điều quan trọng là cân bằng giữa tất cả dimensions (width, depth, resolution) trong quá trình mở rộng ConvNet.
Phương pháp mở rộng được đề xuất
Conv layer i-th có thể được định nghĩa là một hàm $Y_i = F_i(X_i)$, trong đó $F_i$ là toán toán tử, $Y_i$ là tensor đầu ra, $X_i$ là tensor đầu vào với kích thước là $<H_i, W_i, C_i>$, $H_i$, $W_i$ là spatial dimensisons, $C_i$ là số channels. Một ConvNet có thể được định nghĩa bằng danh sách các layer:
\[N = F_k \bigodot F_{k-1} \bigodot ... \bigodot F_1(X_1) = \underset{i=1...k}{\bigodot} F_i(X_1)\]Mạng CNN có thể được coi như việc chồng các convolutional layers lên nhau. Hơn thế nữa các layers này có thể phân chia vào các stages (tầng) khác nhau, ResNet có 5 stages và tất cả các layers trong mỗi stage có chung convolutional type. Do đó mạng CNN có thể được biểu diễn dưới dạng toán học như sau:
\[N = \underset{i=1...s}{\bigodot} F_i^{L_i}(X_{<H_i, W_i, C_i>}) ~~~~~~~~ (1)\]trong đó $N$ miêu tả mạng NN, $i$ biểu diễn số stage (tầng), $F_i$ biểu diễn convolution operation cho i-th stage và $L_i$ biểu diễn số lần $F_i$ được lặp lại trong i-th stage. $H_i, W_i, C_i$ lần lượt miêu tả input tensor shape cho i-th stage.
Từ phương trình (1) $L_i$ kiểm soát độ sâu của mạng, $C_i$ chịu trách nhiệm cho độ rộng của mạng, $H_i$ và $W_i$ ảnh hưởng đến độ phân giải. Việc tìm bộ hệ số tốt để mở rộng các dimensions cho mỗi layer gần như là không thể do không gian tìm kiếm quá lớn. Do đó để giới hạn không gian tìm kiếm nhóm tác giả đã đặt ra một số quy tắc cơ bản:
- Tất cả layers/stages trong mô hình mở rộng sẽ sử dụng cùng convolution operations như mạng cơ sở
- Tất cả layers phải được mở rộng đều với tỉ số không đổi
Với những quy tắc đó, phương trình (1) có thể được tham số hóa như sau:
\[N(d, w, r) = \underset{i=1...s}{\bigodot} \hat{F}_i^{d \cdot \hat{L_i}}(X_{<r \cdot \hat{H_i},r \cdot \hat{W_i}, r \cdot \hat{C_i}>}) ~~~~~~~~ (2)\]trong đó $w$, $d$, $r$ là các hệ số mở rộng mạng tương ứng với độ rộng, độ sâu và độ phân giải. $\hat{F_i}$, $\hat{L_i}$, $\hat{H_i}$, $\hat{W_i}$, $\hat{C_i}$ là những tham số được xác định trước trong mạng cơ sở.
Nhóm tác giả đề xuất kỹ thuật mở rộng đơn giản nhưng hiệu quả có sử dụng hệ số kết hợp (compound coefficient) để mở rộng đều mạng NN theo chiều rộng, chiều sâu và độ phân giải theo một cách có nguyên tắc:
\(\text{depth}: d = \alpha^\phi\) \(\text{width}: w = \beta^\phi\) \(\text{resolution}: r = \gamma^\phi\) \(s.t ~~~ \alpha \cdot \beta^2 \cdot \gamma^2 \approx 2, \alpha \geq 1, \beta \geq 1, \gamma \geq 1\)
Các công thức 3
Hệ số $\phi$ do người dùng tự xác định là hệ số mở rộng toàn bộ (global scaling factor) - kiểm soát lượng tài nguyên có sẵn. Trái lại $\alpha$, $\beta$, $\gamma$ xác định cách phân bố tài nguyên cho độ sâu, độ rộng và độ phân giải của mạng. FLOPS của convolution operation (phép tính tích chập) tỉ lệ với $d$, $w^2$, $r^2$ bởi vì tăng gấp đôi độ sâu sẽ dẫn đến tăng gấp đôi FLOPS trong khi tăng gấp đôi độ rộng hay độ phân giải sẽ tăng FLOPS lên 4 lần. Do đó việc mở rộng mạng NN sử dụng các công thức 3 sẽ tăng tổng số FLOPS lên $(\alpha \cdot \beta^2 \cdot \gamma^2)^\phi$. Vì vậy để chắc chắn tổng số FLOPS không vượt quá $2^\phi$ rằng buộc $(\alpha \cdot \beta^2 \cdot \gamma^2) \approx 2$ được áp dụng. Điều này có nghĩa rằng nếu chúng ta có gấp đôi tài nguyên chúng ta đơn giản có thể sử dụng hệ số kết hợp 1 để mở rộng FLOPS lên $2^1$.
Các tham số $\alpha$, $\beta$, $\gamma$ có thể được xác định bằng cách sử dụng grid search, đặt hệ số kết hợp $\phi = 1$ và tìm bộ tham số để đạt được accuracy cao nhất. Khi tìm được các tham số $\alpha$, $\beta$, $\gamma$ chúng ta có thể cố định chúng lại, hệ số kết hợp $\phi$ có thể được tăng lên để có được model lớn hơn nhưng cũng chính xác hơn. Đây chính là cách EfficientNet-B1 đến EfficientNet-B7 được xây dựng, số nguyên ở cuối của tên model biểu thị giá trị của hệ số kết hợp được sử dụng.
Kết quả
Kỹ thuật mở rộng đã tìm hiểu bên trên cho phép chúng ta tạo ra các model với accuracy cao hơn các ConvNets có sẵn và cũng giúp giảm tổng số FLOPS, model size.
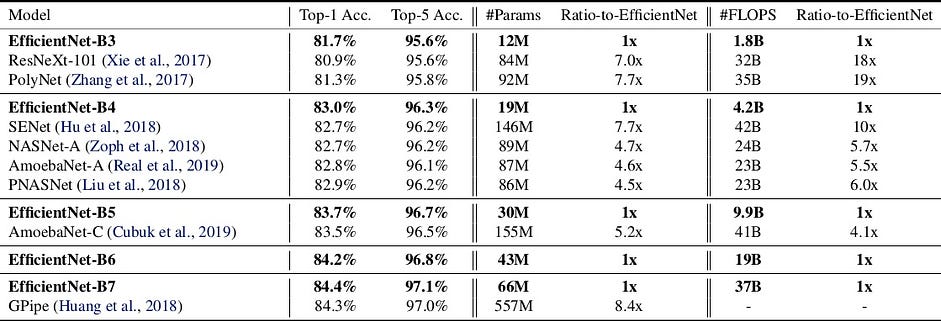
So sánh EfficientNet với các mạng cho ImageNet Challenge
Phương pháp mở rộng này có thể được sử dụng với các kiến trúc khác để mở rộng một cách hiệu quả ConvNet và đạt được accuracy tốt hơn.
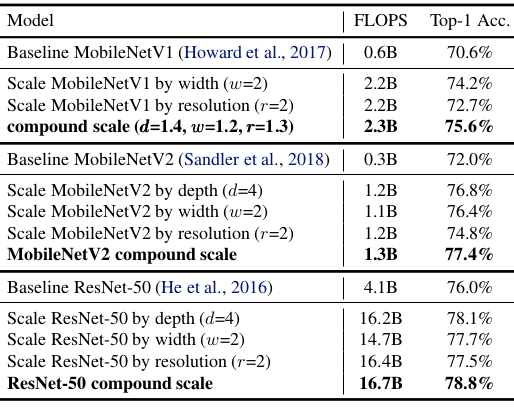
Scaling up MobileNet and ResNet
Tài liệu tham khảo
- https://towardsdatascience.com/efficientnet-scaling-of-convolutional-neural-networks-done-right-3fde32aef8ff
- https://medium.com/@nainaakash012/efficientnet-rethinking-model-scaling-for-convolutional-neural-networks-92941c5bfb95
- https://arxiv.org/abs/1905.11946
- https://viblo.asia/p/efficientnet-cach-tiep-can-moi-ve-model-scaling-cho-convolutional-neural-networks-Qbq5QQzm5D8