
MobileNet Understanding
Ngày nay nhu cầu deploy model lên các thiết bị edge-devices ngày một tăng. Các thiết bị này có tài nguyên tính toán thấp, do đó model của chúng ta không những phải nhẹ mà còn phải đảm bảo độ chính xác chấp nhận được. Vì vậy cần có dạng model nào đó có thể thỏa mãn điều kiện trên.
Trước tiên chúng ta cùng đi tìm hiểu về Normal convolution và Depthwise seperable convolution.
Normal convolution
- Input có kích thước $n \times n \times n_c$
- Filter với kích thước $f \times f \times n_c$ (trong normal convolution số channels của filter bằng số channels của input), số channels là $n_c’$
- Output sẽ có kích thước là $n_{out} \times n_{out} \times n_c’$
Lúc này số tham số cần học là: $f \times f \times n_c \times n_c’$, đây chính là số tham số tương ứng với các filters trong normal convolution.
Chúng ta sẽ tính computational cost (coi là số phép tính phải thực hiện trong normal convolution). Chúng ta có công thức tổng quát:
\[\text{computational~cost} = filter~params \times filter~positions \times filters\] \[\text{computational~cost} = (f \times f \times n_c) \times (n_{out} \times n_{out}) \times n_c'\]Cách hiểu đơn giản của mình như này: computational cost sẽ bằng số phép tính cho một vị trí nhân với số vị trí (spatial dimensions) nhân với số filters.
Có thể hiểu số phép tính là số phép nhân element-wise của filter và input (phép tính gần đúng cho computational cost)
Depthwise seperable convolution
Depthwise seperable convolution gồm 2 thành phần là depthwise convolution (tích chập sâu) và pointwise convolution (tích chập điểm).

Depthwise and pointwise convolution
Depthwise convolution
Như chúng ta đã biết trong normal convolution (tích chập thông thường) filter sẽ có số channels bằng với số channels của input. Số lượng filters chính là số channels của output. Điều này hoàn toàn khác so với depthwise convolution.
Trong depthwise convolution, mỗi filter chỉ có một channel và nó sẽ tương tác với duy nhất một channel trên input. Số filters sẽ bằng với số channels của input. Chi tiết hơn thì:
- Input có kích thước $n \times n \times n_c$
- Filter với kích thước $f \times f$, số channels là $n_c$
- Output sẽ có kích thước là $n_{out} \times n_{out} \times n_c$ (kích thước output để giống bên normal convolution, có padding hay không có padding đều được).
Lúc này số tham số cần học trong depthwise convolution là: $f \times f \times n_c$.
Khi đó ta có:
\[\text{computational~cost} = filter~params \times filter~positions \times filters\] \[\text{computational~cost} = (f \times f) \times (n_{out} \times n_{out}) \times n_c\]Pointwise convolution
Pointwise convolution chính là Conv layer 1x1. Để có thể so sánh được computational cost chúng ta sẽ lấy số filters sao cho output có cùng kích thước với output của normal convolution.
- Input có kích thước $n_{out} \times n_{out} \times n_c$
- Filter với kích thước $1 \times 1 \times n_c$, số channels là $n_c’$
- Output sẽ có kích thước là $n_{out} \times n_{out} \times n_c’$. Như vậy output từ depthwise seperable convolution giống với output của normal convolution.
Lúc này số tham số cần học trong depthwise convolution là: $n_c \times n_c’$. Khi đó ta có:
\[\text{computational~cost} = filter~params \times filter~positions \times filters\] \[\text{computational~cost} = (n_c) \times (n_{out} \times n_{out}) \times n_c'\]Tổng hợp Kết hợp depthwise convolution và pointwise convolution chúng ta có depthwise seperable convolution với computational cost được tính như sau:
\[\text{computational~cost} = (f \times f) \times (n_{out} \times n_{out}) \times n_c + (n_c) \times (n_{out} \times n_{out}) \times n_c'\]Cùng với đó tổng tham số cần học trong depthwise seperable convolution là: $f \times f \times n_c + n_c \times n_c’$.
So sánh computational cost của depthwise seperable convolution và normal convolution:
\[\frac{(f \times f) \times (n_{out} \times n_{out}) \times n_c + (n_c) \times (n_{out} \times n_{out}) \times n_c'}{(f \times f \times n_c) \times (n_{out} \times n_{out}) \times n_c'} = \frac{1}{n_c'} + \frac{1}{f^2}\]So sánh số tham số cần học của depthwise seperable convolution với normal convolution:
\[\frac{f \times f \times n_c + n_c \times n_c'}{f \times f \times n_c \times n_c'} = \frac{1}{n_c'} + \frac{1}{f^2}\]Thường trong các model $f=3$ do đó computational cost và số parameter cần phải học giảm đi khá nhiều. Điều này có thể giúp chúng ta triển khai model trên các edge devices.
MobileNetv1
Ý tưởng chính của MobileNetv1 là thay normal convolution tính toán nặng bằng depthwise seperable convolution. Kiến trúc của MobileNetv1 khá đơn giản Conv layer thông thường đầu tiên sau đó là 13 layer Depthwise seperable convolutions.
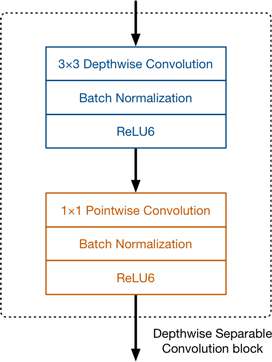
Trong MobileNetv1 không có Pooling layers trong depthwise seperable blocks để giảm spatial dimensions. Thay vào đó ở một số depthwise layers nó sử dụng strides=2 để giảm spatial dimensions. Khi depthwise layer sử dụng strides=2 thì poitwise layer tương ứng cũng tăng số channels của output so với đầu vào của depthwise seperable block. Nếu kích thước ảnh ban đầu là 224x224x3 thì chúng ta có feature map đầu ra là 7x7x1024.
Trong depthwise seperable block dùng activation function ReLU6 là biến thể của ReLU. Tác giả nhận ra rằng ReLU6 mạnh mẽ hơn so với ReLU khi làm việc với low-precision computation.
y = min(max(0, x), 6)
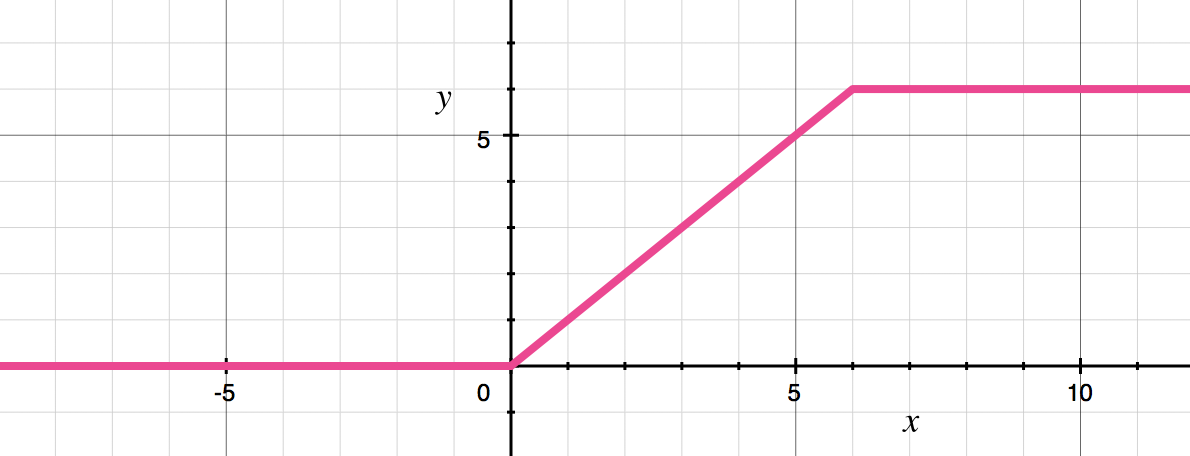
ReLU6
Hình dạng của ReLU6 trông khá giống với hàm sigmoid.
Các lớp cuối cùng của MobileNetv1 là Pooling layer, FC layer và softmax layer.
MobileNetv2
Kiến trúc của MobileNetv2 có thay đổi một chút khi bổ sung thêm skip connection và lớp expansion trong khối block. Expansion layer đơn thuần chỉ là một Conv layer 1x1. Nhiệm vụ của expansion layer là mở rộng số channels của data trước khi đưa vào depthwise Conv layer. Chính xác số channels được mở rộng được xác định thông qua expansion factor - đây là một hyperparamter. Mặc định expansion factor = 6.
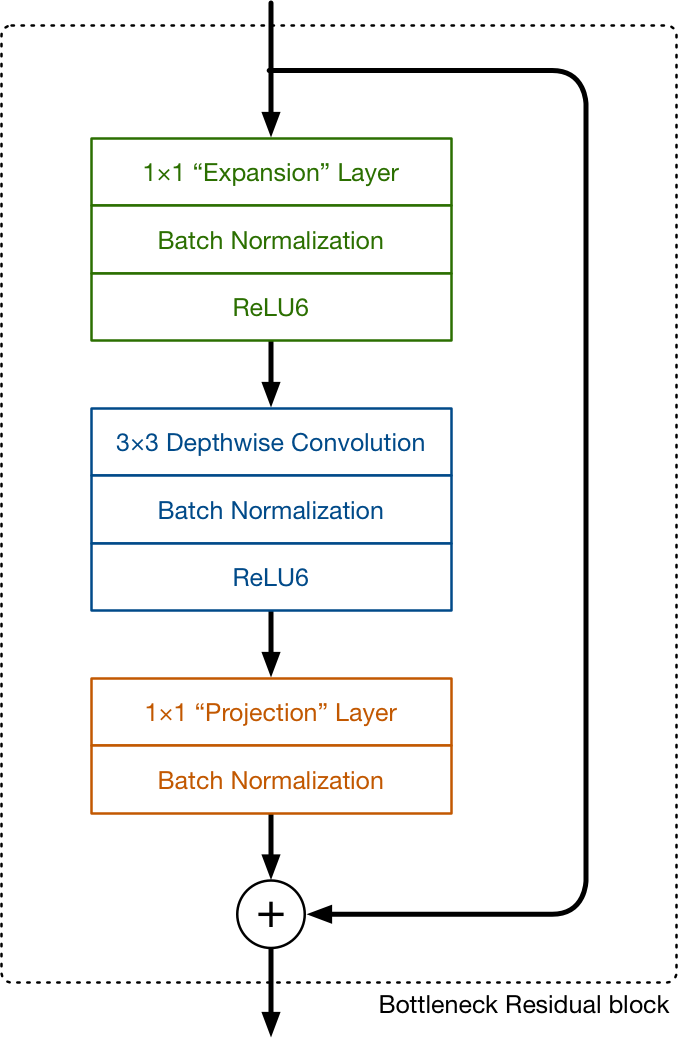
Trong MobileNetv1, pointwise convolution (Conv layer 1x1) hoặc là giữ nguyên hoặc là nhân đôi số channels. Tuy nhiên ở trong MobileNetv2 pointwise convolution lại làm giảm sô channels. Đó chính là lý do nó được gọi là projection layer - chiếu tensor với dimension lớn (ở đây là channels) thành tensor với dimension nhỏ hơn.
Ví dụ depthwise layer có 144 channels đi qua projection layer nó sẽ co (shrink) channels lại còn 24. Những layer như thế này còn được gọi là bottleneck layer. Đó cũng là lý do vì sao block trên có tên là bottleneck residual block (đầu ra của mỗi block là bottleneck + block có sử dụng skip connection).
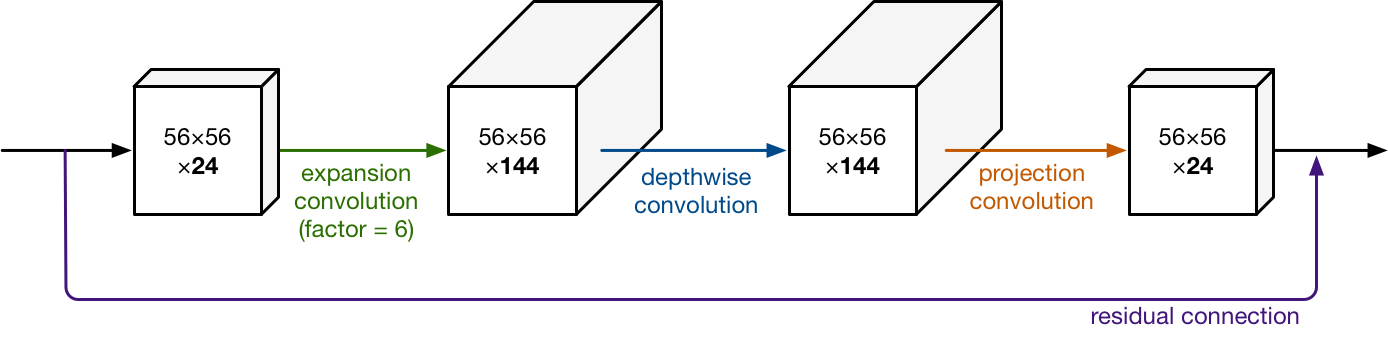
Ví dụ nếu tensor có 24 channels, expansion layer sẽ convert nó thành tensor mới với 24x6=144 channels. Sau đó áp dụng depthwise convolution cho tensor đó, đầu ra vẫn là tensor có 144 channels. Cuối cùng đi qua projection layer, nó sẽ project tensor 144 channles trở lại thành tensor có 24 channels. Nhận thấy input và output của block đều có kích thước nhỏ.
Residual connection chỉ được sử dụng khi số channels của input và output của block như nhau. Tuy nhiên điều này không phải luôn đúng, có một số ít blocks số channels của output lớn hơn số channels của input block.
Nhận thấy trong block các layer đều sử dụng Batch Normalzation, expansion layer, depthwise layer sử dụng activation function ReLU6. Pointwise hay projection layer không suwe dụng nonlinearly activation function do nó có làm giảm các thông tin hữu ích.
Tài liệu tham khảo
- https://machinethink.net/blog/mobilenet-v2/
- https://www.coursera.org/learn/convolutional-neural-networks/home/week/2